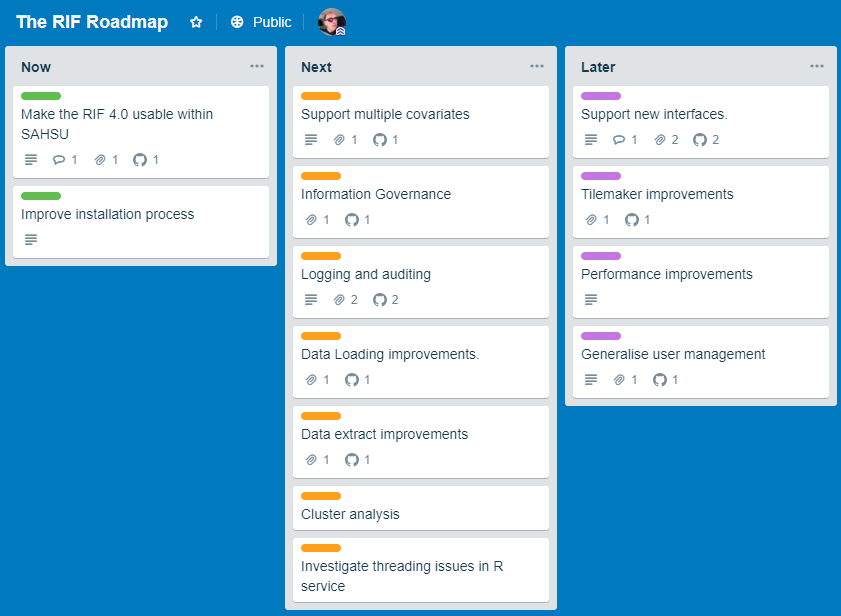
RIF Priorities for the first quarter of 2019 are:
Improve the installation process [MM]
Done. The next step is to add Liquibase support
For the rest of 2019 the focus is currently expected to be on:
This is likely to change to adapt to funder requirements.
See the RIF Roadmap on Trello or as a graphic:
These are a priority for end of April 2019, in priority order:
Issue #127 risk analysis D3 maps. These will replace the posterior probability J curve and the frequency count the FP defined D3 charts displaying the homogeneity data.
Done.
This will be based on the visible displays in the RIF 3.2, for point source exposures (minimum displayed dataset to include observed counts, expected counts, relative risk, trend test for each site, and adjusted by region with heterogeneity testing and meta-analysis function. The content and layout should be discussed with FP:
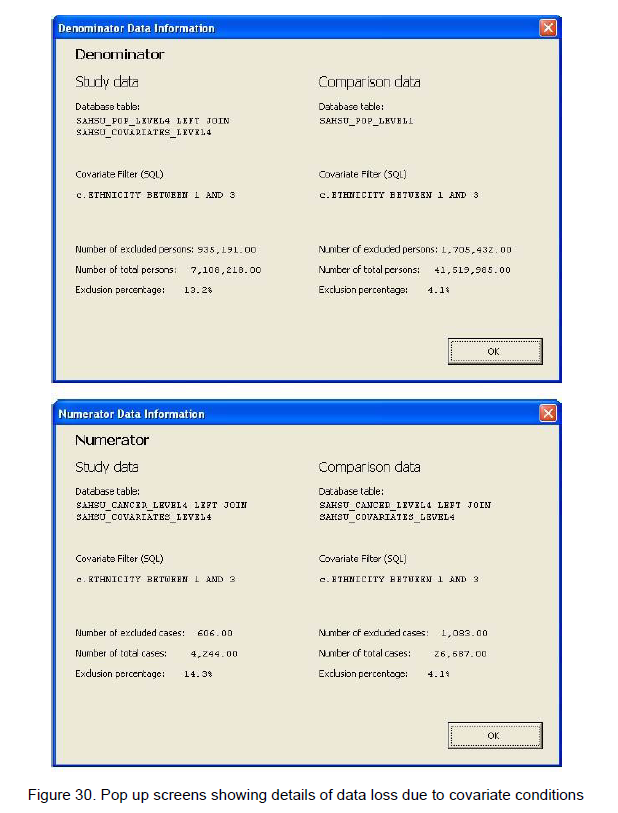
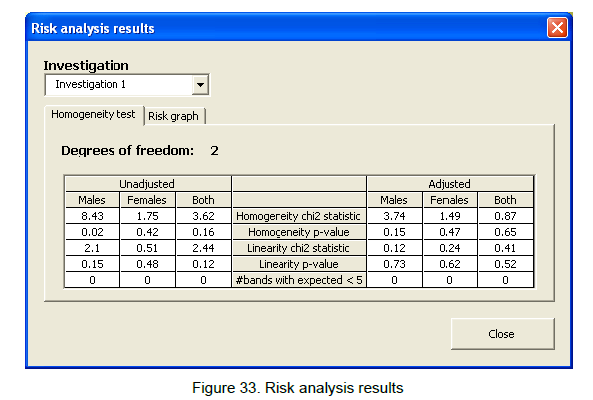
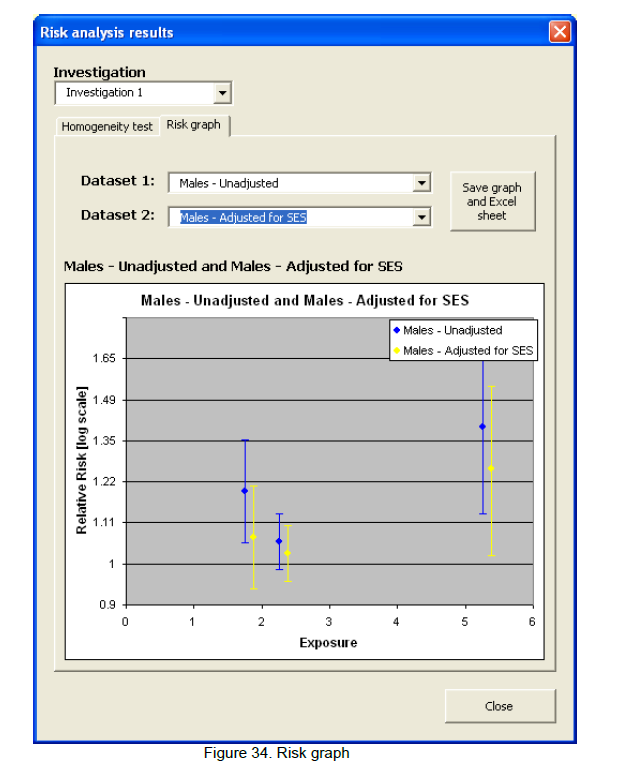 .
.Study summary error appears to be a porting fault and is trivial to fix (rif40 schema is missing):
11:19:09.860 [http-nio-8080-exec-6] ERROR org.sahsu.rif.generic.util.CommonLogger : [org.sahsu.rif.services.datastorage.common.SmoothedResultManager]:
SmoothedResultManager.getHealthCodesForProcessedStudy error
getMessage: SQLServerException: Invalid object name 'rif40_inv_conditions'.
getRootCauseMessage: SQLServerException: Invalid object name 'rif40_inv_conditions'.
getThrowableCount: 1
getRootCauseStackTrace >>>
com.microsoft.sqlserver.jdbc.SQLServerException: Invalid object name 'rif40_inv_conditions'.
at com.microsoft.sqlserver.jdbc.SQLServerException.makeFromDatabaseError(SQLServerException.java:259)
at com.microsoft.sqlserver.jdbc.SQLServerStatement.getNextResult(SQLServerStatement.java:1547)
at com.microsoft.sqlserver.jdbc.SQLServerPreparedStatement.doExecutePreparedStatement(SQLServerPreparedStatement.java:548)
at com.microsoft.sqlserver.jdbc.SQLServerPreparedStatement$PrepStmtExecCmd.doExecute(SQLServerPreparedStatement.java:479)
at com.microsoft.sqlserver.jdbc.TDSCommand.execute(IOBuffer.java:7344)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.executeCommand(SQLServerConnection.java:2713)
at com.microsoft.sqlserver.jdbc.SQLServerStatement.executeCommand(SQLServerStatement.java:224)
at com.microsoft.sqlserver.jdbc.SQLServerStatement.executeStatement(SQLServerStatement.java:204)
at com.microsoft.sqlserver.jdbc.SQLServerPreparedStatement.executeQuery(SQLServerPreparedStatement.java:401)
at org.sahsu.rif.services.datastorage.common.SmoothedResultManager.getHealthCodesForProcessedStudy(SmoothedResultManager.java:387)
at org.sahsu.rif.services.datastorage.common.StudyRetrievalService.getHealthCodesForProcessedStudy(StudyRetrievalService.java:834)
at org.sahsu.rif.services.rest.StudyResultRetrievalServiceResource.getHealthCodesForProcessedStudy(StudyResultRetrievalServiceResource.java:697)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)`
Tasks:
Issue #124 Multiple covariates (first part for March 2019); done.
This will be implemented this in two stages:
Tasks, stage one (one primary covariate, multiple additional covariates):
Tasks, stage two (multiple covariates):
Done.
Front end complete with database changes (11/4/2019). Middleware and R support TODO;
Issue #126 Oracle interconnect. Functionality is already in place, need to confirm that SQL Server works and both ports perform acceptably. Note that this is not considered suitable for denominator or covariate data;
Done.
These are not:
Issue #118 extend PNG tile support to mapping. Adds the ability to use tiles instead of GeoJSON in the front end, Currently only integrated to the when load a large area study from a JSON file.
For geolevels with more than 5000 areas the RIF middleware can auto generate PNG tiles on startup. Tiles are then cached;
Issue #115 Improve the installation process. There should be as few manual interactions as possible. Preferably none, though obviously the user giving details at the start is fine. A middleware installer executable would be excellent;
Done.
This is likely to change to adapt to funder requirements.
Issue #124 Multiple covariates (first part for March 2019); See above. This will focus on the statistical support.
Done.
SQL> @find_all_privs.sql
FIND_ALL_PRIVS: Release 1.3.0.0.0 - Production - (http://www.petefinnigan.com)
Copyright (c) 2004 PeteFinnigan.com Limited. All rights reserved.
get user input
NAME OF USER TO CHECK [ORCL]: OUTLN
OUTPUT METHOD Screen/File [S]:
FILE NAME FOR OUTPUT [priv.lst]:
OUTPUT DIRECTORY [/tmp]:
USER => OUTLN has ROLE CONNECT which contains =>
SYS PRIV =>ALTER SESSION grantable => NO
SYS PRIV =>CREATE CLUSTER grantable => NO
SYS PRIV =>CREATE DATABASE LINK grantable => NO
SYS PRIV =>CREATE SEQUENCE grantable => NO
SYS PRIV =>CREATE SESSION grantable => NO
SYS PRIV =>CREATE SYNONYM grantable => NO
SYS PRIV =>CREATE TABLE grantable => NO
SYS PRIV =>CREATE VIEW grantable => NO
USER => OUTLN has ROLE RESOURCE which contains =>
SYS PRIV =>CREATE CLUSTER grantable => NO
SYS PRIV =>CREATE INDEXTYPE grantable => NO
SYS PRIV =>CREATE OPERATOR grantable => NO
SYS PRIV =>CREATE PROCEDURE grantable => NO
SYS PRIV =>CREATE SEQUENCE grantable => NO
SYS PRIV =>CREATE TABLE grantable => NO
SYS PRIV =>CREATE TRIGGER grantable => NO
SYS PRIV =>CREATE TYPE grantable => NO
SYS PRIV =>EXECUTE ANY PROCEDURE grantable => NO
SYS PRIV =>UNLIMITED TABLESPACE grantable => NO
TABLE PRIV =>EXECUTE table_name => OUTLN_PKG grantable => NO
PL/SQL procedure successfully completed.
Issue #81 improve the audit trail; Add t_rif40_warnings/rif40_warnings table and view to contain warning messages on a study basis. Can be created by the extract or R the scripts. Add traps for:
Add Java processing log, SQL statement and warnings logs to extract.
Issue #86 logging; Modernise the logging, switching to SLF4J and Logback; and also vastly improve the internal handling of, particularly, Exceptions see also issue #46. Logging of SQL Exceptions needs to include:
The current scripts for creating a RIF database rely on a core set of scripts, and up to 14 alter scripts. The alter script in particular cause dependency issues when they modify trigger SQL. This needs to be resolved so that the RIF can manage its own data structures and to remove dependency issue using Git version control and dynamic triggers:
This is estimated at about 3 months work.
Data loader tools - issues #84
A new simple loading tool that is part of the main RIF web application that just loads data in a predefined format directly into the database. The tool would be a “Data Loading” tab on the main RIF screen, visible only the users with the rif_manager role. It would have four new icons similar to the tree focused on:
It would be able to:
Longer term the data loader tool could support more formats, e.g. typical SAHSU study extracts or CDC datasets and the loading of covariates and denominator data.
Support for geographies would require the tileMaker functionality to be moved into the RIF - see below and Issue #91 Tilemaker updates.
Issue #123 improve search in taxonomies. The taxonomy search can be confusing when users search by an ICD code. The search currently finds any occurrence of the entered string anywhere in either the code or the description.
Proposal - split the search into two:
That should be two separate search boxes, aligned above the corresponding columns in the results table. If the user enters values in both boxes they will be AND-ed together.
The latest version of UI-Grid support hierarchies which will improve the look of the Taxonomy search table.
Behaviour:
MM thinks both fields should use simple “contains” searches, like the present one. If the entered value occurs anywhere in the corresponding field, the data will be returned.
An alternative is to use some system of wildcards, even going as far as supporting regular expressions, but providing the separated boxes will remove the need for that, and supporting those kinds of features would make things more complex for users.
Issue to be created
Reference:
The original code used WinBugs; would require an R version.
Issue to be created
R service is single threaded. Possible options are:
Issue #82 Support New Interfaces
New technical features will include
BREEZE AERMOD / ISC and Wind roses are new input forms for risk analysis band selection.
Issue #83 SATScan. Satscan and LinBUGS/WinBUGS be supported via the extract ZIP file - i.e. create a script to run them and produce worked examples. Satscan is available as an R package rstatscan but this calls statscan and therefore is limited to Windows only Tomcats. The R package SpatialEpi contains a function called kulldorff, which performs the purely spatial scan statistic with either the Poisson or Bernoulli probability model. The package also contains many other useful methods that are unrelated to scan statistics and not part of the SaTScan software.
TileMaker is currently working with some minor faults but needs to:
Convert Tile Maker to Java application; integrate to main RIF front end.
This would be a longer term objective to fully integrate Tile manufacturing into the main RIF. It requires support for simplification and TopoJSON generation in one of:
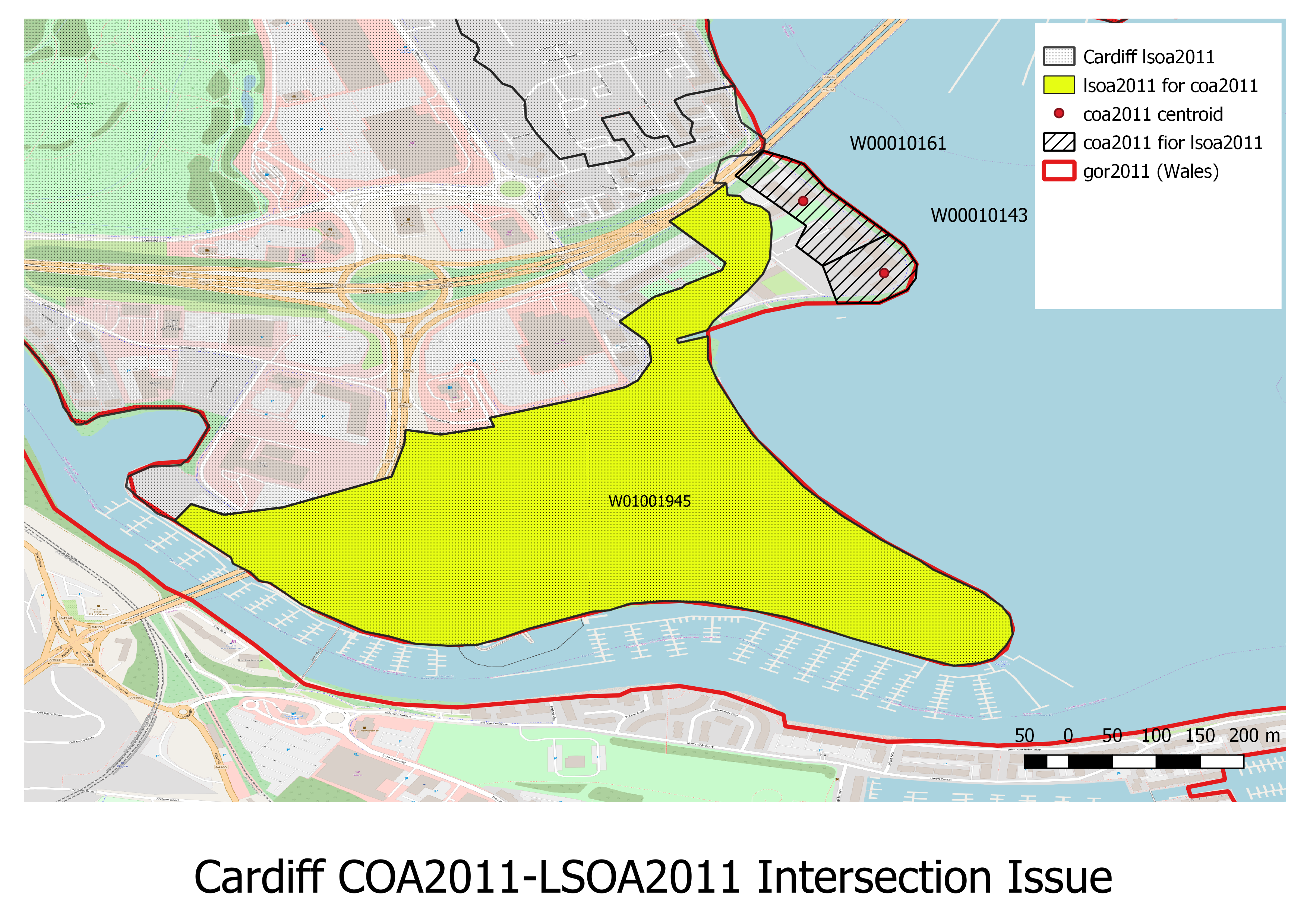
To be in the hierarchy the intersection code insert_hierarchy.sql selects the intersection with the largest intersection by area for each (higher resolution). This eliminates duplicates and picks the most likely intersection on the basis of area. There are two possible reasons for this failure:
Currently the hierarchy intersector intersects by the largest area; so where there is an overlap the correct area is chosen. However missing intersctions, typically missing Islands (e.g. Lidingö Kommun does not intersect: https://en.wikipedia.org/wiki/Liding%C3%B6 Stockholm county) or reclaimed ground (e.g. Cardiff docks COAs W00010161 and W00010143 are missing from the LSOA intersction). These have to be fixed by hand by inserting the correct intersction; an algorithm to pick the nearest shape by centroid is required.
Gottröra parish in STOCKHOLM (a level3) is not included because the level4 area includes two level3’s and the neighbour was picked as it was bigger, so was deleted. This has to be the only action when this occurs and is likely to cause issues with geocoded data where of course both level3’s can be used. Fixed by deleting the smaller parish. This can be logically detected and added to the processing.
Issue #80 optimise performance on large datasets. This work is envisaged to require:
Issue #102 Generalise user management
This is to add documentation to the manuals for the use of:
Issue #79 TileMaker Unicode area names - SQL Server only. Some examples from the US geography in Puerto Rico:
Postgres works fine. Previous fix to NVARCHAR(1000) has worked. SQL Server is still wrong. Problems is therefore in the SQL Server database. Effects database, hopefully not the various Java/Javascript drivers.
Postgres (correct):
sahsuland=> SELECT areaname from lookup_cb_2014_us_county_500k where cb_2014_us_county_500k = '01804540';
areaname
------------
Río Grande
(1 row)
SQL Server (wrong):
1> SELECT areaname from rif_data.lookup_cb_2014_us_county_500k where cb_2014_us_county_500k = '01804540';
2> go
areaname
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
R+-ío Grande
(1 rows affected)

The columns are all NVARCHAR(1000) all the way back to the initial load table. They indicates an issue with BULK INSERT the SQL Server load command Use Unicode Character Format to Import or Export Data:;
console.log, console.debug calls not testing if the browser is open. Most RIF and library code is safe; believed to be the
proj4.js Javascript library http://proj4js.org/;ERROR: No health data for theme "SAHSU land cancer incidence example data", geography "EWS2011".
ERROR: Could not retrieve your project information from the database: unable to get numerator/denominator pair