Database Management Manual
- Overview
- User Management
- Creating new users
- Postgres
- Manually creating a new user
- SQL Server
- Manually creating a new user
- Changing passwords
- Postgres
- SQL Server
- Proxy accounts
- Postgres
- SQL Server
- Granting permission
- Postgres
- SQL Server
- Viewing your user setup
- Postgres
- SQL Server
- Data Management
- Creating new schemas
- Postgres
- SQL Server
- Tablespaces
- Postgres
- SQL Server
- Partitioning
- Postgres
- SQL Server
- Granting permission
- Postgres
- SQL Server
- Remote Database Access
- Postgres with a remote Oracle database
- SQL Server with a remote Oracle database
- Postgres with a remote SQL Server database
- SQL Server with a remote Postgres database
- Information Governance
- Auditing
- Postgres
- SQL Server
- Backup and recovery
- Postgres
- Logical Backups
- Continuous Archiving and Point-in-Time Recovery
- SQL Server
- Logical Backups
- Continuous Archiving and Point-in-Time Recovery
- Patching
- Postgres
- SQL Server
- Tuning
- Postgres
- Server Memory Tuning
- Query Tuning
- Database Space Management
- SQL Server
- Server Memory Tuning
- Query Tuning
- Database Space Management
Overview
This manual details how to manage RIF databases. See also the:
User Management
Creating new users
New users must be created in lower case, start with a letter, and only contain the characters: [a-z][0-9]_. Do not use mixed case, upper case, dashes, space or non
ASCII e.g. UTF8) characters. Beware; the database stores user names internally in upper case. This is because of the RIF’s Oracle heritage.
Postgres
Run the optional script rif40_production_user.sql. This creates a default user %newuser% with password %newpw% in database %newdb% from the command environment.
This is set from the command line using the -v newuser= -v newpw= and -v newdb= parameters. Run as a normal user or an
Administrator, using the *postgres* account:
psql -U postgres -d postgres -w -e -f rif40_production_user.sql -v newuser=kevin -v newpw=nivek -v newdb=sahsuland
- User is created with the rif_user (can create tables and views) and rif_manager roles (can also create procedures and functions);
- User can use the sahsuland database;
- Will fail to re-create a user if the user already has objects (tables, views etc);
Test connection and object privileges, access to RIF numerators and denominators:
C:\Users\phamb\Documents\GitHub\rapidInquiryFacility>psql -U kevin
Password for user kevin:
You are connected to database "sahsuland" as user "kevin" on host "localhost" at port "5432".
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: rif40_log_setup() DEFAULTED send DEBUG to INFO: off; debug function list: []
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00000.03s rif40_startup(): SQL> SET search_path TO kevin,rif40, public, topology, gis, pop, rif_data, data_load, rif40_sql_pkg, rif_studies, rif40_partitions,rif_studies;
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00000.06s rif40_startup(): SQL> DROP FUNCTION IF EXISTS kevin.rif40_run_study(INTEGER, INTEGER);
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: NOTICE: function kevin.rif40_run_study(pg_catalog.int4,pg_catalog.int4) does not exist, skipping
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00000.14s rif40_startup(): Created temporary table: g_rif40_study_areas
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00000.16s rif40_startup(): Created temporary table: g_rif40_comparison_areas
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00001.00s rif40_startup(): PostGIS extension V2.3.5 (POSTGIS="2.3.5 r16110" GEOS="3.6.2-CAPI-1.10.2 4d2925d" PROJ="Rel. 4.9.3, 15 August 2016" GDAL="GDAL 2.2.2, released 2017/09/15" LIBXML="2.7.8" LIBJSON="0.12" RASTER)
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00001.02s rif40_startup(): FDW functionality disabled - FDWServerName, FDWServerType, FDWDBServer RIF parameters not set.
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00001.03s rif40_startup(): V$Revision: 1.11 $ rif40_geographies, rif40_tables, rif40_health_study_themes exist for user: kevin
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00001.03s rif40_startup(): VIEW rif40_user_version not found; rebuild forced
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00001.03s rif40_startup(): search_path: rif40, public, topology, gis, pop, rif_data, data_load, rif40_sql_pkg, rif_studies, rif40_partitions, rif_studies, reset: rif40, public, topology, gis, pop, rif_data, data_load, rif40_sql_pkg, rif_studies, rif40_partitions
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: analyzing "kevin.t_rif40_num_denom"
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: "t_rif40_num_denom": scanned 0 of 0 pages, containing 0 live rows and 0 dead rows; 0 rows in sample, 0 estimated total rows
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00001.15s rif40_startup(): Created table: t_rif40_num_denom
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00001.29s rif40_startup(): Created view: rif40_num_denom_errors
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00001.34s rif40_startup(): Created view: rif40_num_denom
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00001.34s rif40_startup(): V$Revision: 1.11 $ Creating view: rif40_user_version
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00001.36s rif40_startup(): Deleted 0, created 6 tables/views/foreign data wrapper tables
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: SQL> SET search_path TO kevin,rif40, public, topology, gis, pop, rif_data, data_load, rif40_sql_pkg, rif_studies, rif40_partitions;
DO
psql (9.6.8)
Type "help" for help.
sahsuland=> SELECT current_database() AS db_name INTO test_table;
SELECT 1
sahsuland=> SELECT * FROM test_table;
db_name
-----------
sahsuland
(1 row)
sahsuland=> SELECT * FROM rif40_num_denom;
geography | numerator_table | numerator_description | theme_description | denominator_table | denominator_description | automatic
-----------+----------------------+-----------------------------------------------+-----------------------------------+-------------------+------------------------------------------------------------------------------------------+-----------
SAHSULAND | NUM_SAHSULAND_CANCER | cancer numerator | covering various types of cancers | POP_SAHSULAND_POP | population health file | 1
(1 row)
sahsuland=> \q
C:\Users\phamb\Documents\GitHub\rapidInquiryFacility>
Manually creating a new user
These instructions are based on rif40_production_user.sql. This uses NEWUSER and NEWDB from the CMD environment.
- Change “mydatabasename” to the name of your database, e.g. sahsuland;
- Change “mydatabasenuser” to the name of your user, e.g. peter;
- Change “mydatabasepassword” to the name of your users password;
- Validate the RIF user; connect as user postgres on the database postgres:
DO LANGUAGE plpgsql $$
BEGIN
IF current_user != 'postgres' OR current_database() != 'postgres' THEN
RAISE EXCEPTION 'rif40_production_user.sql() current_user: % and current database: % must both be postgres', current_user, current_database();
END IF;
END;
$$;
- Create Login; connect as user postgres on the database mydatabasename (.e.g. sahsuland):
DO LANGUAGE plpgsql $$
DECLARE
c2 CURSOR(l_usename VARCHAR) FOR
SELECT * FROM pg_user WHERE usename = l_usename;
c3 CURSOR FOR
SELECT CURRENT_SETTING('rif40.nnewpw') AS nnewpw,
CURRENT_SETTING('rif40.newpw') AS newpw;
c4 CURSOR(l_name VARCHAR, l_pass VARCHAR) FOR
SELECT rolpassword::Text AS rolpassword,
'md5'||md5(l_pass||l_name)::Text AS password
FROM pg_authid
WHERE rolname = l_name;
c1_rec RECORD;
c2_rec RECORD;
c3_rec RECORD;
c4_rec RECORD;
--
sql_stmt VARCHAR;
u_name VARCHAR;
u_pass VARCHAR;
u_database VARCHAR;
BEGIN
u_name:='mydatabasenuser';
u_pass:='mydatabasepassword';
u_database:='mydatabasename';
--
-- Test account exists
--
OPEN c2(u_name);
FETCH c2 INTO c2_rec;
CLOSE c2;
IF c2_rec.usename IS NULL THEN
RAISE NOTICE 'C209xx: User account does not exist: %; creating', u_name;
sql_stmt:='CREATE ROLE '||u_name||
' NOSUPERUSER NOCREATEDB NOCREATEROLE INHERIT LOGIN NOREPLICATION PASSWORD '''||
CURRENT_SETTING('rif40.newpw')||'''';
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
ELSE
--
OPEN c4(u_name, u_pass);
FETCH c4 INTO c4_rec;
CLOSE c4;
IF c4_rec.rolpassword IS NULL THEN
RAISE EXCEPTION 'C209xx: User account: % has a NULL password',
c2_rec.usename;
ELSIF c4_rec.rolpassword != c4_rec.password THEN
RAISE INFO 'rolpassword: "%"', c4_rec.rolpassword;
RAISE INFO 'password(%): "%"', u_pass, c4_rec.password;
RAISE EXCEPTION 'C209xx: User account: % password (%) would change; set password correctly', c2_rec.usename, u_pass;
ELSE
RAISE NOTICE 'C209xx: User account: % password is unchanged',
c2_rec.usename;
END IF;
--
IF pg_has_role(c2_rec.usename, 'rif_user', 'MEMBER') THEN
RAISE INFO 'rif40_production_user.sql() user account="%" is a rif_user', c2_rec.usename;
ELSIF pg_has_role(c2_rec.usename, 'rif_manager', 'MEMBER') THEN
RAISE INFO 'rif40_production_user.sql() user account="%" is a rif manager', c2_rec.usename;
ELSE
RAISE EXCEPTION 'C209xx: User account: % is not a rif_user or rif_manager', c2_rec.usename;
END IF;
END IF;
--
sql_stmt:='GRANT CONNECT ON DATABASE '||u_database||' to '||u_name;
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
sql_stmt:='GRANT rif_manager TO '||u_name;
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
sql_stmt:='GRANT rif_user TO '||u_name;
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
END;
$$;
- Create user and grant roles:
DO LANGUAGE plpgsql $$
DECLARE
sql_stmt VARCHAR;
u_name VARCHAR;
u_database VARCHAR;
BEGIN
u_name:='mydatabasenuser';
u_database:='mydatabasename';
IF user = 'postgres' AND current_database() = u_database THEN
RAISE INFO 'User check: %', user;
ELSE
RAISE EXCEPTION 'C209xx: User check failed: % is not postgres on % database (%)',
user, u_database, current_database();
END IF;
--
sql_stmt:='GRANT CONNECT ON DATABASE '||u_database||' to '||u_name;
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
sql_stmt:='CREATE SCHEMA IF NOT EXISTS '||u_name||' AUTHORIZATION '||u_name;
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
END;
$$;
- Change the password. The password is set to mydatabasepassword.
The user specific object views: rif40_num_denom, rif40_num_denom_errors are automatically created. These must be created as the user so they run with the users
privileges and therefore only return RIF data tables to which the user has been granted access permission.
SQL Server
Run the optional script rif40_production_user.sql. This creates a default user %newuser% with password %newpw% in database %newdb% from the command environment.
This is set from the command line using the -v newuser= -v newpw= and -v newdb= parameters. Run as *Administrator*:
sqlcmd -E -b -m-1 -e -i rif40_production_user.sql -v newuser=kevin -v newpw=XXXXXXXXXXXX -v newdb=sahsuland
- User is created with the rif_user (can create tables and views) and rif_manager roles (can also create procedures and functions);
- User can use the sahsuland database;
- Will fail to re-create a user if the user already has objects (tables, views etc);
Test connection and object privileges, access to RIF numerators and denominators:
C:\Users\Peter\Documents\GitHub\rapidInquiryFacility\rifDatabase\Postgres\psql_scripts>sqlcmd -U kevin -P XXXXXXXXXXXX
1> SELECT db_name() AS db_name INTO test_table;
2> SELECT * FROM test_table;
3> go
(1 rows affected)
db_name
--------------------------------------------------------------------------------------------------------------------------------
rif40
(1 rows affected)
1> SELECT * FROM rif40_num_denom;
2> go
geography numerator_table numerator_description theme_description denominator_table denominator_description automatic
-------------------------------------------------- ------------------------------ ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ------------------------------ ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ---------
SAHSULAND NUM_SAHSULAND_CANCER cancer numerator covering various types of cancers POP_SAHSULAND_POP population health file 1
(1 rows affected)
1> quit
C:\Users\Peter\Documents\GitHub\rapidInquiryFacility\rifDatabase\Postgres\psql_scripts>
Manually creating a new user
These instructions are based on rif40_production_user.sql. This uses NEWUSER and NEWDB from the CMD environment.
- Change “mydatabasename” to the name of your database, e.g. sahsuland;
- Change “mydatabasenuser” to the name of your user, e.g. peter;
- Change “mydatabasepassword” to the name of your users password;
- Validate the RIF user
USE [master];
GO
DECLARE @newuser VARCHAR(MAX)='mydatabaseuser';
DECLARE @invalid_chars INTEGER;
DECLARE @first_char VARCHAR(1);
SET @invalid_chars=PATINDEX('%[^0-9a-z_]%', @newuser);
SET @first_char=SUBSTRING(@newuser, 1, 1);
IF @invalid_chars IS NULL
RAISERROR('New username is null', 16, 1, @newuser);
ELSE IF @invalid_chars > 0
RAISERROR('New username: %s contains invalid character(s) starting at position: %i.', 16, 1,
@newuser, @invalid_chars);
ELSE IF (LEN(@newuser) > 30)
RAISERROR('New username: %s is too long (30 characters max).', 16, 1, @newuser);
ELSE IF ISNUMERIC(@first_char) = 1
RAISERROR('First character in username: %s is numeric: %s.', 16, 1, @newuser, @first_char);
ELSE
PRINT 'New username: ' + @newuser + ' OK';
GO
- Create Login
USE [master];
GO
IF NOT EXISTS (SELECT * FROM sys.sql_logins WHERE name = N'mydatabaseuser')
CREATE LOGIN [mydatabaseuser] WITH PASSWORD='mydatabasepassword', CHECK_POLICY = OFF;
GO
ALTER LOGIN [mydatabaseuser] WITH DEFAULT_DATABASE = [mydatabasename];
GO
- Creare user and grant roles
USE mydatabasename;
GO
BEGIN
IF NOT EXISTS (SELECT name FROM sys.database_principals WHERE name = N'mydatabaseuser')
CREATE USER [mydatabaseuser] FOR LOGIN [mydatabaseuser] WITH DEFAULT_SCHEMA=[dbo]
ELSE ALTER USER [mydatabaseuser] WITH LOGIN=[mydatabasepassword];
--
-- Object privilege grants
--
GRANT CREATE TABLE TO [mydatabaseuser];
GRANT CREATE VIEW TO [mydatabaseuser];
--
IF NOT EXISTS (SELECT name FROM sys.schemas WHERE name = N'mydatabaseuser')
EXEC('CREATE SCHEMA [mydatabaseuser] AUTHORIZATION [mydatabasepassword]');
ALTER USER [mydatabaseuser] WITH DEFAULT_SCHEMA=[mydatabaseuser];
ALTER ROLE rif_user ADD MEMBER [mydatabaseuser];
ALTER ROLE rif_manager ADD MEMBER [mydatabaseuser];
END;
GO
- Change the password. The password is set to mydatabasepassword.
- Create user specific object views: rif40_num_denom, rif40_num_denom_errors. These must be created as the user so they run with the users privileges and therefore only return
RIF data tables to which the user has been granted access permission.
USE mydatabasename;
GO
--
-- RIF40 num_denom, rif40_num_denom_errors
--
-- needs functions:
-- rif40_is_object_resolvable
-- rif40_num_denom_validate
-- rif40_auto_indirect_checks
--
IF EXISTS (SELECT * FROM sys.objects
WHERE object_id = OBJECT_ID(N'[mydatabaseuser].[rif40_num_denom]') AND type in (N'V'))
BEGIN
DROP VIEW [mydatabaseuser].[rif40_num_denom]
END
GO
CREATE VIEW [mydatabaseuser].[rif40_num_denom] AS
WITH n AS (
SELECT n1.geography,
n1.numerator_table,
n1.numerator_description,
n1.automatic,
n1.theme_description
FROM ( SELECT g.geography,
n_1.table_name AS numerator_table,
n_1.description AS numerator_description,
n_1.automatic,
t.description AS theme_description
FROM [rif40].[rif40_geographies] g,
[rif40].[rif40_tables] n_1,
[rif40].[rif40_health_study_themes] t
WHERE n_1.isnumerator = 1 AND n_1.automatic = 1
AND [rif40].[rif40_is_object_resolvable](n_1.table_name) = 1
AND n_1.theme = t.theme) n1
WHERE [rif40].[rif40_num_denom_validate](n1.geography, n1.numerator_table) = 1
), d AS (
SELECT d1.geography,
d1.denominator_table,
d1.denominator_description
FROM ( SELECT g.geography,
d_1.table_name AS denominator_table,
d_1.description AS denominator_description
FROM [rif40].[rif40_geographies] g,
[rif40].[rif40_tables] d_1
WHERE d_1.isindirectdenominator = 1
AND d_1.automatic = 1
AND [rif40].[rif40_is_object_resolvable](d_1.table_name) = 1) d1
WHERE [rif40].[rif40_num_denom_validate](d1.geography, d1.denominator_table) = 1
AND [rif40].[rif40_auto_indirect_checks](d1.denominator_table) IS NULL
)
SELECT n.geography,
n.numerator_table,
n.numerator_description,
n.theme_description,
d.denominator_table,
d.denominator_description,
n.automatic
FROM n,
d
WHERE n.geography = d.geography
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Numerator and indirect standardisation denominator pairs. Use RIF40_NUM_DENOM_ERROR if your numerator and denominator table pair is missing. You must have your own copy of RIF40_NUM_DENOM or you will only see the tables RIF40 has access to. Tables not rejected if the user does not have access or the table does not contain the correct geography geolevel fields.' ,
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW', @level1name=N'rif40_num_denom'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Geography',
@level0type=N'SCHEMA', @level0name=N'mydatabaseuser', @level1type=N'VIEW', @level1name=N'rif40_num_denom',
@level2type=N'COLUMN',@level2name=N'geography'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Numerator table',
@level0type=N'SCHEMA', @level0name=N'mydatabaseuser', @level1type=N'VIEW', @level1name=N'rif40_num_denom',
@level2type=N'COLUMN',@level2name=N'numerator_table'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Numerator table description',
@level0type=N'SCHEMA', @level0name=N'mydatabaseuser', @level1type=N'VIEW', @level1name=N'rif40_num_denom',
@level2type=N'COLUMN',@level2name=N'numerator_description'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Numerator table health study theme description',
@level0type=N'SCHEMA', @level0name=N'mydatabaseuser', @level1type=N'VIEW', @level1name=N'rif40_num_denom',
@level2type=N'COLUMN',@level2name=N'theme_description'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Denominator table',
@level0type=N'SCHEMA', @level0name=N'mydatabaseuser', @level1type=N'VIEW', @level1name=N'rif40_num_denom',
@level2type=N'COLUMN',@level2name=N'denominator_table'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Denominator table description',
@level0type=N'SCHEMA', @level0name=N'mydatabaseuser', @level1type=N'VIEW', @level1name=N'rif40_num_denom',
@level2type=N'COLUMN',@level2name=N'denominator_description'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Is the pair automatic (0/1). Cannot be applied to direct standardisation denominator. Restricted to 1 denominator per geography. The default in RIF40_TABLES is 0 because of the restrictions.' ,
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW', @level1name=N'rif40_num_denom',
@level2type=N'COLUMN',@level2name=N'automatic'
GO
IF EXISTS (SELECT * FROM sys.objects
WHERE object_id = OBJECT_ID(N'[mydatabaseuser].[rif40_num_denom_errors]') AND type in (N'V'))
BEGIN
DROP VIEW [mydatabaseuser].[rif40_num_denom_errors]
END
GO
CREATE VIEW [mydatabaseuser].[rif40_num_denom_errors] AS
WITH n AS (
SELECT n1.geography,
n1.numerator_table,
n1.numerator_description,
n1.automatic,
n1.is_object_resolvable,
n1.n_num_denom_validated,
n1.numerator_owner
FROM ( SELECT g.geography,
n_1.table_name AS numerator_table,
n_1.description AS numerator_description,
n_1.automatic,
[rif40].[rif40_is_object_resolvable](n_1.table_name) AS is_object_resolvable,
[rif40].[rif40_num_denom_validate](g.geography, n_1.table_name) AS n_num_denom_validated,
[rif40].[rif40_object_resolve](n_1.table_name) AS numerator_owner
FROM [rif40].[rif40_geographies] g,
[rif40].[rif40_tables] n_1
WHERE n_1.isnumerator = 1 AND n_1.automatic = 1) n1
), d AS (
SELECT d1.geography,
d1.denominator_table,
d1.denominator_description,
d1.is_object_resolvable,
d1.d_num_denom_validated,
d1.denominator_owner,
[rif40].[rif40_auto_indirect_checks](d1.denominator_table) AS auto_indirect_error
FROM ( SELECT g.geography,
d_1.table_name AS denominator_table,
d_1.description AS denominator_description,
[rif40].[rif40_is_object_resolvable](d_1.table_name) AS is_object_resolvable,
[rif40].[rif40_num_denom_validate](g.geography, d_1.table_name) AS d_num_denom_validated,
[rif40].[rif40_object_resolve](d_1.table_name) AS denominator_owner
FROM [rif40].[rif40_geographies] g,
[rif40].[rif40_tables] d_1
WHERE d_1.isindirectdenominator = 1 AND d_1.automatic = 1) d1
)
SELECT n.geography,
n.numerator_owner,
n.numerator_table,
n.is_object_resolvable AS is_numerator_resolvable,
n.n_num_denom_validated,
n.numerator_description,
d.denominator_owner,
d.denominator_table,
d.is_object_resolvable AS is_denominator_resolvable,
d.d_num_denom_validated,
d.denominator_description,
n.automatic,
CASE
WHEN d.auto_indirect_error IS NULL THEN 0
ELSE 1
END AS auto_indirect_error_flag,
d.auto_indirect_error /*,
f.create_status AS n_fdw_create_status,
f.error_message AS n_fdw_error_message,
f.date_created AS n_fdw_date_created,
f.rowtest_passed AS n_fdw_rowtest_passed */
FROM d,
n
WHERE n.geography = d.geography;
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'All possible numerator and indirect standardisation denominator pairs with error diagnostic fields. As this is a CROSS JOIN the will be a lot of output as tables are not rejected on the basis of user access or containing the correct geography geolevel fields.' ,
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW',@level1name=N'rif40_num_denom_errors'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Geography',
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW',@level1name=N'rif40_num_denom_errors',
@level2type=N'COLUMN',@level2name=N'geography'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Numerator table owner' ,
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW',@level1name=N'rif40_num_denom_errors',
@level2type=N'COLUMN',@level2name=N'numerator_owner'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Numerator table' ,
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW',@level1name=N'rif40_num_denom_errors',
@level2type=N'COLUMN',@level2name=N'numerator_table'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Is the numerator table resolvable and accessible (0/1)' ,
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW',@level1name=N'rif40_num_denom_errors',
@level2type=N'COLUMN',@level2name=N'is_numerator_resolvable'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Is the numerator valid for this geography (0/1). If N_NUM_DENOM_VALIDATED and D_NUM_DENOM_VALIDATED are both 1 then the pair will appear in RIF40_NUM_DENOM.',
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW',@level1name=N'rif40_num_denom_errors',
@level2type=N'COLUMN',@level2name=N'n_num_denom_validated'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Numerator table description',
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW',@level1name=N'rif40_num_denom_errors',
@level2type=N'COLUMN',@level2name=N'numerator_description'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Denominator table owner',
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW',@level1name=N'rif40_num_denom_errors',
@level2type=N'COLUMN',@level2name=N'denominator_owner'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Denominator table',
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW',@level1name=N'rif40_num_denom_errors',
@level2type=N'COLUMN',@level2name=N'denominator_table'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Is the denominator table resolvable and accessible (0/1)',
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW',@level1name=N'rif40_num_denom_errors',
@level2type=N'COLUMN',@level2name=N'is_denominator_resolvable'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Is the denominator valid for this geography (0/1). If N_NUM_DENOM_VALIDATED and D_NUM_DENOM_VALIDATED are both 1 then the pair will appear in RIF40_NUM_DENOM.',
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW',@level1name=N'rif40_num_denom_errors',
@level2type=N'COLUMN',@level2name=N'd_num_denom_validated'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Denominator table description',
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW',@level1name=N'rif40_num_denom_errors',
@level2type=N'COLUMN',@level2name=N'denominator_description'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Is the pair automatic (0/1). Cannot be applied to direct standardisation denominator. Restricted to 1 denominator per geography. The default in RIF40_TABLES is 0 because of the restrictions.',
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW',@level1name=N'rif40_num_denom_errors',
@level2type=N'COLUMN',@level2name=N'automatic'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Error flag 0/1. Denominator table with automatic set to "1" that fails the RIF40_CHECKS.RIF40_AUTO_INDIRECT_CHECKS test. Restricted to 1 denominator per geography to prevent the automatic RIF40_NUM_DENOM having >1 pair per numerator.',
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW',@level1name=N'rif40_num_denom_errors',
@level2type=N'COLUMN',@level2name=N'auto_indirect_error_flag'
GO
EXEC sys.sp_addextendedproperty @name=N'MS_Description',
@value=N'Denominator table with automatic set to "1" that fails the RIF40_CHECKS.RIF40_AUTO_INDIRECT_CHECKS test. Restricted to 1 denominator per geography to prevent the automatic RIF40_NUM_DENOM having >1 pair per numerator. List of geographies and tables in error.',
@level0type=N'SCHEMA',@level0name=N'mydatabaseuser', @level1type=N'VIEW',@level1name=N'rif40_num_denom_errors',
@level2type=N'COLUMN',@level2name=N'auto_indirect_error'
GO
Changing passwords
Valid characters for passwords have been tested as: [A-Z][a-z][0-9]!@$^~_-. Passwords must be up to 30 characters long; longer passwords may be supported. The following are definitely NOT
valid: SQL Server/ODBC special characters: []{}(),;?*=!@.
Use of special characters]: \/&% is not advised as command line users will need to use an escaping URI to connect.
Postgres
The file .pgpass in a user’s home directory or the file referenced by PGPASSFILE can contain passwords to be used if the connection requires a password
(and no password has been specified otherwise). On Microsoft Windows the file is named %APPDATA%\postgresql\pgpass.conf (where %APPDATA% refers to the
Application Data subdirectory in the user’s profile).
This file should contain lines of the following format:
hostname:port:database:username:password
You can add a comment to the file by preceding the line with #. Each of the first four fields can be a literal value, or *, which matches anything. The password field from the first line
that matches the current connection parameters will be used. (Therefore, put more-specific entries first when you are using wildcards.)
If an entry needs to contain : or \, escape this character with . A host name of localhost matches both TCP (host name localhost) and Unix domain socket
(pghost empty or the default socket directory) connections coming from the local machine.
On Unix systems, the permissions on .pgpass must disallow any access to world or group; achieve this by the command chmod 0600 ~/.pgpass. If the permissions are less strict
than this, the file will be ignored. On Microsoft Windows, it is assumed that the file is stored in a directory that is secure, so no special permissions check is made.
If you change a users password and you use the user from the command line (typically postgres, rif40 and the test username) change it in the <pgpass> file.
Notes:
- Your normal user and the administrator account will have separate <pgpass> files;
- The postgres account password is set by the Postgres (EnterpriseDB) installler. This password is not set in the Administrator <pgpass> file.;
- The rif40 and the test username are both set by the database install script to <username><5 digit random number><5 digit random number>.
These passwords are set in the Administrator <pgpass> file.;
- No passwords are set in the normal user <pgpass> file;
To change a Postgres password:
ALTER ROLE rif40 WITH PASSWORD 'XXXXXXXX';
SQL Server
To change a SQL server password:
ALTER LOGIN rif40 WITH PASSWORD = 'XXXXXXXX';
GO
Proxy accounts
Proxy accounts are of use to the RIF as it can allow a normal user to login as a schema owner. Good practice is not the set the schema owner passwords (e.g. rif40) as these tend to be known by
several people and tend to get written down as these accounts are infrequently used. Proxy accounts allow for privilege minimisation. Importantly the use proxy accounts is fully audited, in
particular the privilege escalation (i.e. use of the proxy).
The SAHSU Private network uses proxying for these reasons.
The RIF front end application and middleware use user name and passwords to authenticate. Therefore federated mechanism such as Kerberos and
SSPI (Windows authentication) will not work; and would require
a GSSAPI implementation in the middleware. Invariably substantial browser and server key
set-up is required and this is very difficult to set up (some years ago the SAHSU private network used this for five years; the experiment was not repeated).
Postgres
If you need to integrate into you Active Directory or authentication services you are advised to use LDAP.
This permits user name and password authentication; ldap does not support proxying. Login to the database using the command lines can then use SSPI and this can then be proxied
to allow schema access. See Postgres LDAP Authentication and
LDAP Authentication against AD
Postgres proxy accounts are controlled by pg_ident.conf in the Postgres data directory. See
Postgres Client Authentication
The map name must be one of following mappable methods from hba.conf (i.e. that support proxying):
- ident: Identification Protocol as described in RFC 1413 (INSECURE: DO NOT USE)
- peer: Peer authentication is only available on operating systems providing the getpeereid() function, the SO_PEERCRED socket parameter, or similar mechanisms. Currently that includes Linux, most flavors of BSD including OS X, and Solaris.
- gss: GSSAPI/Kerberos
- pam: Linux PAM (Pluggable authentication modules)
- sspi: Windows native autentiation (NTLM V2)
- cert: Uses SSL client certificates to perform authentication. It is therefore only available for SSL connections.
The Windows installer guide for Postgres has examples:
So, if I setup SSPI as per the examples to use SSPI in hba.conf:
#
# Active directory GSSAPI connections with pg_ident.conf maps for schema accounts
#
hostssl sahsuland all 127.0.0.1/32 sspi map=sahsuland
hostssl sahsuland all ::1/128 sspi map=sahsuland
hostssl sahsuland_dev all 127.0.0.1/32 sspi map=sahsuland_dev
hostssl sahsuland_dev all ::1/128 sspi map=sahsuland_dev
With the maps sahsuland and sahsuland_dev defined in ident.conf:
# MAPNAME SYSTEM-USERNAME PG-USERNAME
#
sahsuland pch pop
sahsuland pch gis
sahsuland pch rif40
sahsuland pch pch
#
sahsuland_dev pch pop
sahsuland_dev pch gis
sahsuland_dev pch rif40
sahsuland_dev pch pch
sahsuland_dev pch postgres
Set the RIF40 password to an impossible value:
ALTER ROLE rif40 WITH PASSWORD 'md5ac4bbe016b8XXXXXXXXXX6981f240dcae';
Finally, optioanlly add the passwords to the
Pgpass file.
I can then logon as rif40 using SSPI:
C:\Users\phamb\OneDrive\SEER Data>psql -U rif40
You are connected to database "sahsuland" as user "rif40" on host "localhost" at port "5432".
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: rif40_log_setup() DEFAULTED send DEBUG to INFO: off; debug function list: []
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00000.01s rif40_startup(): search_path not set for: rif40
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00000.01s rif40_startup(): SQL> DROP FUNCTION IF EXISTS rif40.rif40_run_study(INTEGER, INTEGER);
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: NOTICE: function rif40.rif40_run_study(pg_catalog.int4,pg_catalog.int4) does not exist, skipping
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00000.06s rif40_startup(): Created temporary table: g_rif40_study_areas
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00000.08s rif40_startup(): Created temporary table: g_rif40_comparison_areas
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00000.15s rif40_startup(): PostGIS extension V2.3.5 (POSTGIS="2.3.5 r16110" GEOS="3.6.2-CAPI-1.10.2 4d2925d" PROJ="Rel. 4.9.3, 15 August 2016" GDAL="GDAL 2.2.2, released 2017/09/15" LIBXML="2.7.8" LIBJSON="0.12" RASTER)
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00000.15s rif40_startup(): FDW functionality disabled - FDWServerName, FDWServerType, FDWDBServer RIF parameters not set.
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00000.15s rif40_startup(): V$Revision: 1.11 $ DB version $Revision: 1.11 $ matches
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00000.15s rif40_startup(): V$Revision: 1.11 $ rif40_geographies, rif40_tables, rif40_health_study_themes exist for user: rif40
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00000.15s rif40_startup(): search_path: public, topology, gis, pop, rif_data, data_load, rif40_sql_pkg, rif_studies, rif40_partitions, reset: rif40, public, topology, gis, pop, rif_data, data_load, rif40_sql_pkg, rif_studies, rif40_partitions
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00000.16s rif40_startup(): Deleted 0, created 2 tables/views/foreign data wrapper tables
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: SQL> SET search_path TO rif40, public, topology, gis, pop, rif_data, data_load, rif40_sql_pkg, rif_studies, rif40_partitions;
DO
psql (9.6.8)
Type "help" for help.
sahsuland=>
SQL Server
This needs to be investigated as it is not certain SQL Server has the correct functionality and the setup would need to be trialled. See:
Granting permission
The RIF is setup so that three roles control access to the application:
- rif_user: User level access to the application with full access to data at the highest resolution.
No ability to change the RIF configuration or to add more data;
- rif_manager: Manager level access to the application with full access to data at the highest resolution.
Ability to change the RIF configuration. No ability by default to add data to the RIF. Data is normally added
using the schema owner account (rif40); see the above section on proxying to access the schema account user
a manager accounts credentials.
- rif_student. Restricted access to the application with controlled access to data at the higher resolutions.
No ability to change the RIF configuration or to add more data;
Access to data is controlled by the permissions granted to that data and not by the RIF.
- In the SAHSULAND example database data access is granted to rif_user, rif_manager and rif_student.
- In the SEER dataset data access is granted to seer_user.
Postgres
To create the SEER_USER role and grant it to a user (peter) logon as the administrator (postgres):
psql -U postgres -d postgres
CREATE ROLE seer_user;
GRANT seer_user TO peter;
SQL Server
To create the SEER_USER role and grant it to a user (peter) logon as the administrator in an Administrator
cmd window:
sqlcmd -E
USE sahsuland;
IF DATABASE_PRINCIPAL_ID('seer_user') IS NULL
CREATE ROLE [seer_user];
SELECT name, type_desc FROM sys.database_principals WHERE name LIKE '%seer_user%';
ALTER ROLE [seer_user] ADD MEMBER [peter];
GO
Viewing your user setup
Postgres
To view roles, privileges and role membership:
C:\Users\phamb\OneDrive\SEER Data>psql -U postgres -d sahsuland
You are connected to database "sahsuland" as user "postgres" on host "localhost" at port "5432".
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: +00000.12s rif40_startup(): disabled - user postgres is not or has rif_user or rif_manager role
psql:C:/Program Files/PostgreSQL/9.6/etc/psqlrc:48: INFO: SQL> SET search_path TO postgres,rif40, public, topology, gis, pop, rif_data, data_load, rif40_sql_pkg, rif_studies, rif40_partitions;
DO
psql (9.6.8)
Type "help" for help.
sahsuland-# \du
List of roles
Role name | Attributes | Member of
-------------------------+------------------------------------------------------------+----------------------------------
gis | | {}
kevin | | {rif_manager,rif_user}
notarifuser | | {}
peter | | {rif_manager,rif_user,seer_user}
pop | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
rif40 | | {}
rif_manager | Cannot login | {}
rif_no_suppression | Cannot login | {}
rif_student | Cannot login | {}
rif_user | Cannot login | {}
rifupg34 | Cannot login | {}
seer_user | Cannot login | {}
test_rif_manager | | {rif_manager}
test_rif_no_suppression | | {rif_no_suppression}
test_rif_student | | {rif_student}
test_rif_user | | {rif_user}
To view roles and permissions granted to an object:
sahsuland-# \dp rif40_tables
Access privileges
Schema | Name | Type | Access privileges | Column privileges | Policies
--------+--------------+-------+------------------------+-------------------+----------
rif40 | rif40_tables | table | rif40=arwdDxt/rif40 +| |
| | | rif_manager=arwd/rif40+| |
| | | =rx/rif40 | |
(1 row)
Where the access privileges (+ is a line continuation character) are:
- r: SELECT (“read”)
- w: UPDATE (“write”)
- a: INSERT (“append”)
- d: DELETE
- D: TRUNCATE
- x: REFERENCES
- t: TRIGGER
- X: EXECUTE
- U: USAGE
- C: CREATE
- c: CONNECT
- T: TEMPORARY
SQL Server
To view roles, as an administrator sqlcmd -E -d sahsuland:
SELECT name, type_desc, default_schema_name, authentication_type_desc
FROM sys.database_principals;
GO
name type_desc default_schema_name authentication_type_desc
-------------------------------------------------------------------------------------------------------------------------------- ------------------------------------------------------------ -------------------------------------------------------------------------------------------------------------------------------- ------------------------------------------------------------
public DATABASE_ROLE NULL NONE
dbo WINDOWS_USER dbo WINDOWS
guest SQL_USER guest NONE
INFORMATION_SCHEMA SQL_USER NULL NONE
sys SQL_USER NULL NONE
rif40 SQL_USER rif40 INSTANCE
rif_manager DATABASE_ROLE NULL NONE
rif_user DATABASE_ROLE NULL NONE
rif_student DATABASE_ROLE NULL NONE
rif_no_suppression DATABASE_ROLE NULL NONE
notarifuser DATABASE_ROLE NULL NONE
peter SQL_USER peter INSTANCE
seer_user DATABASE_ROLE NULL NONE
db_owner DATABASE_ROLE NULL NONE
db_accessadmin DATABASE_ROLE NULL NONE
db_securityadmin DATABASE_ROLE NULL NONE
db_ddladmin DATABASE_ROLE NULL NONE
db_backupoperator DATABASE_ROLE NULL NONE
db_datareader DATABASE_ROLE NULL NONE
db_datawriter DATABASE_ROLE NULL NONE
db_denydatareader DATABASE_ROLE NULL NONE
db_denydatawriter DATABASE_ROLE NULL NONE
(22 rows affected)
To view server roles, as an administrator sqlcmd -E -d sahsuland:
SELECT sys.server_role_members.role_principal_id, role.name AS RoleName,
sys.server_role_members.member_principal_id, member.name AS MemberName
FROM sys.server_role_members
JOIN sys.server_principals AS role
ON sys.server_role_members.role_principal_id = role.principal_id
JOIN sys.server_principals AS member
ON sys.server_role_members.member_principal_id = member.principal_id;
GO
role_principal_id RoleName member_principal_id MemberName
----------------- ------------- ------------------- --------------------------------------------------------------------------------------------------------------------------------
3 sysadmin 1 sa
3 sysadmin 259 DESKTOP-4P2SA80\admin
3 sysadmin 260 NT SERVICE\SQLWriter
3 sysadmin 261 NT SERVICE\Winmgmt
3 sysadmin 262 NT Service\MSSQLSERVER
3 sysadmin 264 NT SERVICE\SQLSERVERAGENT
10 bulkadmin 286 rif40
10 bulkadmin 287 peter
(8 rows affected)
To view role membership, as an administrator sqlcmd -E -d sahsuland:
SELECT DP1.name AS DatabaseRoleName, isnull (DP2.name, 'No members') AS DatabaseUserName
FROM sys.database_role_members AS DRM
RIGHT OUTER JOIN sys.database_principals AS DP1
ON DRM.role_principal_id = DP1.principal_id
LEFT OUTER JOIN sys.database_principals AS DP2
ON DRM.member_principal_id = DP2.principal_id
WHERE DP1.type = 'R'
ORDER BY DP1.name;
DatabaseRoleName DatabaseUserName
-------------------------------------------------------------------------------------------------------------------------------- -----------------
db_accessadmin No members
db_backupoperator No members
db_datareader No members
db_datawriter No members
db_ddladmin No members
db_denydatareader No members
db_denydatawriter No members
db_owner dbo
db_securityadmin No members
notarifuser No members
public No members
rif_manager peter
rif_no_suppression No members
rif_student No members
rif_user peter
seer_user peter
(16 rows affected)
To view roles and permissions granted to an object, as an administrator sqlcmd -E -d sahsuland:
sp_helprotect @username = 'peter'
GO
Owner Object Grantee Grantor ProtectType Action Column
---------------------- -------------------- ---------- ---------- ----------- -------------------------------- ------------------
rif_studies s1_extract peter rif40 Grant Delete .
rif_studies s1_extract peter rif40 Grant Insert .
rif_studies s1_extract peter rif40 Grant Select (All+New)
rif_studies s1_map peter rif40 Grant Insert .
rif_studies s1_map peter rif40 Grant Select (All+New)
rif_studies s1_map peter rif40 Grant Update (All+New)
rif_studies s2_extract peter rif40 Grant Delete .
rif_studies s2_extract peter rif40 Grant Insert .
rif_studies s2_extract peter rif40 Grant Select (All+New)
rif_studies s2_map peter rif40 Grant Insert .
rif_studies s2_map peter rif40 Grant Select (All+New)
rif_studies s2_map peter rif40 Grant Update (All+New)
rif_studies s3_extract peter rif40 Grant Delete .
rif_studies s3_extract peter rif40 Grant Insert .
rif_studies s3_extract peter rif40 Grant Select (All+New)
rif_studies s3_map peter rif40 Grant Insert .
rif_studies s3_map peter rif40 Grant Select (All+New)
rif_studies s3_map peter rif40 Grant Update (All+New)
rif_studies s4_extract peter rif40 Grant Delete .
rif_studies s4_extract peter rif40 Grant Insert .
rif_studies s4_extract peter rif40 Grant Select (All+New)
rif_studies s4_map peter rif40 Grant Insert .
rif_studies s4_map peter rif40 Grant Select (All+New)
rif_studies s4_map peter rif40 Grant Update (All+New)
rif_studies s5_extract peter rif40 Grant Delete .
rif_studies s5_extract peter rif40 Grant Insert .
rif_studies s5_extract peter rif40 Grant Select (All+New)
rif_studies s5_map peter rif40 Grant Insert .
rif_studies s5_map peter rif40 Grant Select (All+New)
rif_studies s5_map peter rif40 Grant Update (All+New)
. . peter dbo Grant CONNECT .
. . peter dbo Grant Create Function .
. . peter dbo Grant Create Procedure .
. . peter dbo Grant Create Table .
. . peter dbo Grant Create View .
. . peter dbo Grant SHOWPLAN .
(36 rows affected)
Data Management
Creating new schemas
The RIF install scripts create all the schemas required by the RIF. SQL Server does not have a search path or SYNONYNs so all schemas are hard coded.
Postgres
See: CREATE SCHEMA. Normally schema schema is owned by a role (e.g. rif40) and then
access is granted as required to other roles. New schemas will needs to be added to the default search path either for the roles or possibly at the system level.
Care needs to be taken *NOT to break the RIF. The default search path for a RIF database isL:
ALTER DATABASE sahsuland SET search_path TO rif40, public, topology, gis, pop, rif_data, data_load, rif40_sql_pkg, rif_studies, rif40_partitions;
DO NOT MOVE RIF objects in the following schemas without extensive testing for hard coded schemas:
- rif40, rif_data, rif40_sql_pkg, rif_studies
The users schema is prepended to the search path on login:
sahsuland=> show search_path;
search_path
-------------------------------------------------------------------------------------------------------------
peter, rif40, public, topology, gis, pop, rif_data, data_load, rif40_sql_pkg, rif_studies, rif40_partitions
(1 row)
THEREFORE BEWARE OF CREATING OBJECTS WITH THE SAME NAME AS A RIF OBJECT on Postgres. They will be used in preference to the RIF40 schema object!
SQL Server
SQL Server does not have a search path or SYNONYNs so all schemas are hard coded and locations should NOT be changed.
Tablespaces
Postgres
Tablespaces in PostgreSQL allow database administrators to define locations in the file system where the files representing database objects can be stored. Once created, a
tablespace can be referred to by name when creating database objects.
By using tablespaces, an administrator can control the disk layout of a PostgreSQL installation. This is useful in at least two ways. First, if the partition or volume on
which the cluster was initialized runs out of space and cannot be extended, a tablespace can be created on a different partition and used until the system can be reconfigured.
Second, tablespaces allow an administrator to use knowledge of the usage pattern of database objects to optimize performance. For example, an index which is very heavily used
can be placed on a very fast, highly available disk, such as an expensive solid state device. At the same time a table storing archived data which is rarely used or not performance critical could be stored on a less expensive, slower disk system.
See: Tablespaces
SQL Server
SQL Server does not have the concept of tablespaces.
Partitioning
The SAHSU version 3.1 RIF was extensively partitioned; in particular the calculation tables and the result table rif_results needed to be partitioned on system that had run thousands of
studies will many millions of result rows and billions of extract calculation rows. Hash partitioning was retro fitted to the RIF calculation and results tables and this gave a useful
performance gain.
The new V4.0 RIF uses separate extract and results tables so does not need partitioning of the internal tables. The geometry tables on Postgres are partitioned and this gave a useful
performance gain.
The SAHSU Oracle database performance has benefited from:
- Complete partitioning of all health, population and covariate data;
- Allowing the use of limited parallelisation in queries, inserts and index creation;
- Use of index organised denominator and covariate tables. Note that by default all tables are index organised on SQL Server;
The RIF currently [deliberately] extracts data year by year and so explicit disables effective parallelisation in the extract.
Postgres
Currently only the geometry tables, e.g. rif_data.geometry_sahsuland are partitioned using inheritance and custom triggers.
Postgres 10 has native support for partitioning, see: Postgres 10 partitioning.
The implementation is still incomplete and the following limitations apply to partitioned tables:
- There is no facility available to create the matching indexes on all partitions automatically. Indexes must be added to each partition with separate commands. This also means that
there is no way to create a primary key, unique constraint, or exclusion constraint spanning all partitions; it is only possible to constrain each leaf partition individually.
- Since primary keys are not supported on partitioned tables, foreign keys referencing partitioned tables are not supported, nor are foreign key references from a partitioned table
to some other table.
- Using the ON CONFLICT clause with partitioned tables will cause an error, because unique or exclusion constraints can only be created on individual partitions. There is no support
for enforcing uniqueness (or an exclusion constraint) across an entire partitioning hierarchy.
- An UPDATE that causes a row to move from one partition to another fails, because the new value of the row fails to satisfy the implicit partition constraint of the original partition.
- Row triggers, if necessary, must be defined on individual partitions, not the partitioned table.
See Postgres Patching
for a description of historic Postgres partitioning. The partitioning on the geometry tables uses the range
partitioning schema but generates the code directly. This functionality is part of the tile maker.
The following partitioning limitations are scheduled to be fixed in Postgres 11:
- Executor-stage partition pruning or faster child table pruning or parallel partition processing (i.e. partition elimination using bind variables). This in particular will effect the
RIF as the year by year extract uses bind variables and will probably not partition eliminate correctly;
- Hash partitioning;
- UPDATEs that cause rows to move from one partition to another;
- Support for routing tuples to partitions that are foreign tables;
- Support for index constraints, such as UNIQUE, across the entire partition tree; indexes need to be defined on the individual leaf partitions (unique indexes span only the individual partitions);
- Support for referencing regular tables from partitioned parent tables;
- Support for “catch-all” / “fallback” / “default” partition.
There is no support currently planned for:
- Referencing partitioned parent tables in foreign key relationships;
- “Splitting” or “merging” partitions using dedicated commands;
- Automatic creation of partitions (e.g. for values not covered).
An example of Postgres 10 native partitioning. With Postgres each partition has to be created manually:
--
-- Create EWS2011_POPULATION denominator table
--
CREATE UNLOGGED TABLE rif_data.ews2011_population
(
year INTEGER NOT NULL,
coa2011 VARCHAR(10) NOT NULL,
age_sex_group INTEGER NOT NULL, -- RIF age_sex_group 1 (21 bands),
population NUMERIC(5,1) NULL,
cntry2011 VARCHAR(10) NOT NULL,
gor2011 VARCHAR(10) NOT NULL,
ladua2011 VARCHAR(10) NOT NULL,
msoa2011 VARCHAR(10) NOT NULL,
lsoa2011 VARCHAR(10) NOT NULL,
scntry2011 VARCHAR(10) NOT NULL
) PARTITION BY LIST (year);
--
-- Create partitions
--
DO LANGUAGE plpgsql $$
DECLARE
sql_stmt VARCHAR;
i INTEGER;
BEGIN
FOR i IN 1981 .. 2014 LOOP
sql_stmt:='CREATE TABLE rif_data.ews2011_population_y'||i||' PARTITION OF rif_data.ews2011_population
FOR VALUES IN ('||i||')';
--
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
END LOOP;
END;
$$;
--
-- Load data using \copy
--
\copy rif_data.ews2011_population FROM 'ews2011_population.csv' WITH CSV HEADER;
DO LANGUAGE plpgsql $$
DECLARE
sql_stmt VARCHAR;
i INTEGER;
BEGIN
FOR i IN 1981 .. 2014 LOOP
--
-- Add constraints
--
sql_stmt:='ALTER TABLE rif_data.ews2011_population_y'||i||' ADD CONSTRAINT ews2011_population_y'||i||'_pk'||
' PRIMARY KEY (coa2011, age_sex_group)';
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
sql_stmt:='ALTER TABLE rif_data.ews2011_population_y'||i||' ADD CONSTRAINT ews2011_population_y'||i||'_asg_ck'||
' CHECK (age_sex_group >= 100 AND age_sex_group <= 121 OR age_sex_group >= 200 AND age_sex_group <= 221)';
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
--
-- Convert to index organised table
--
sql_stmt:='CLUSTER rif_data.ews2011_population_y'||i||' USING ews2011_population_y'||i||'_pk';
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
--
-- Indexes
--
sql_stmt:='CREATE INDEX ews2011_population_y'||i||'_age_sex_group'||
' ON rif_data.ews2011_population_y'||i||'(age_sex_group)';
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
sql_stmt:='CREATE INDEX ews2011_population_y'||i||'_scntry2011'||
' ON rif_data.ews2011_population_y'||i||'(scntry2011)';
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
sql_stmt:='CREATE INDEX ews2011_population_y'||i||'_cntry2011'||
' ON rif_data.ews2011_population_y'||i||'(cntry2011)';
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
sql_stmt:='CREATE INDEX ews2011_population_y'||i||'_gor2011'||
' ON rif_data.ews2011_population_y'||i||'(gor2011)';
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
sql_stmt:='CREATE INDEX ews2011_population_y'||i||'_ladua2011'||
' ON rif_data.ews2011_population_y'||i||'(ladua2011)';
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
sql_stmt:='CREATE INDEX ews2011_population_y'||i||'_msoa2011'||
' ON rif_data.ews2011_population_y'||i||'(msoa2011)';
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
sql_stmt:='CREATE INDEX ews2011_population_y'||i||'_lsoa2011'||
' ON rif_data.ews2011_population_y'||i||'(lsoa2011)';
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
--
-- Analyze
--
sql_stmt:='ANALYZE rif_data.ews2011_population_y'||i;
RAISE INFO 'SQL> %;', sql_stmt::VARCHAR;
EXECUTE sql_stmt;
END LOOP;
END;
$$;
SQL Server
SQL Server supports table and index partitioning, see Partitioned Tables and Indexes
Beware of the SQL Server partitioning and licensing conditions;
you may need a full enterprise license.
An example of SQL Server native partitioning:
- Create the partition function and scheme as an administrator:
CREATE PARTITION FUNCTION [pf_ews2011_population_year](SMALLINT) AS RANGE LEFT FOR VALUES (
1981, 1982, 1983, 1984, 1985, 1986, 1987, 1988, 1989,
1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999,
2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009,
2010, 2011, 2012, 2013, 2014);
GO
CREATE PARTITION SCHEME [pf_ews2011_population_year] AS PARTITION [pf_ews2011_population_year] ALL TO ([PRIMARY])
GO
- Create the objects as the schema owner:
--
-- Create EWS2011_POPULATION denominator table
--
CREATE TABLE rif_data.ews2011_population
(
year SMALLINT NOT NULL,
coa2011 VARCHAR(10) NOT NULL,
age_sex_group INTEGER NOT NULL, -- RIF age_sex_group 1 (21 bands)
population NUMERIC(5,1),
cntry2011 VARCHAR(10) NOT NULL,
gor2011 VARCHAR(10) NOT NULL,
ladua2011 VARCHAR(10) NOT NULL,
lsoa2011 VARCHAR(10) NOT NULL,
msoa2011 VARCHAR(10) NOT NULL,
scntry2011 VARCHAR(2) NOT NULL,
CONSTRAINT ews2011_population_pk PRIMARY KEY (year, coa2011, age_sex_group)
) ON pf_ews2011_population_year (year) WITH (DATA_COMPRESSION = PAGE);
GO
--
-- Load data using BULK INSERT
--
BULK INSERT rif_data.ews2011_population
FROM '$(pwd)\ews2011_population.csv' -- Note use of pwd; set via -v pwd="%cd%" in the sqlcmd command line
WITH
(
FIRSTROW = 2,
FORMATFILE = '$(pwd)\ews2011_population.fmt', -- Use a format file
TABLOCK -- Table lock
);
GO
--
-- Enable constraints
--
ALTER TABLE rif_data.ews2011_population ADD CONSTRAINT ews2011_population_asg_ck CHECK (age_sex_group >= 100 AND age_sex_group <= 121 OR age_sex_group >= 200 AND age_sex_group <= 221);
GO
--
-- Partitioned Indexes
--
CREATE INDEX ews2011_population_age_sex_group ON rif_data.ews2011_population(age_sex_group) ON pf_ews2011_population_year (year);
GO
CREATE INDEX ews2011_population_ews2011_cntry2011 ON rif_data.ews2011_population (cntry2011) ON pf_ews2011_population_year (year);
GO
CREATE INDEX ews2011_population_ews2011_gor2011 ON rif_data.ews2011_population (gor2011) ON pf_ews2011_population_year (year);
GO
CREATE INDEX ews2011_population_ews2011_ladua2011 ON rif_data.ews2011_population (ladua2011) ON pf_ews2011_population_year (year);
GO
CREATE INDEX ews2011_population_ews2011_lsoa2011 ON rif_data.ews2011_population (lsoa2011) ON pf_ews2011_population_year (year);
GO
CREATE INDEX ews2011_population_ews2011_msoa2011 ON rif_data.ews2011_population (msoa2011) ON pf_ews2011_population_year (year);
GO
Granting permission
Tables or views may be granted directly to the user or indirectly via a role. Good administration proactive is to grant via a role.
To grant via a role, you must first create a role. for example create and GRANT seer_user role to a user peter:
Postgres
Logon as the Postgres saperuser postgres” or other role with the *superuser privilege.
psql -U postgres -d postgres
CREATE ROLE seer_user;
GRANT seer_user TO peter;
There is no CREATE ROLE IF NOT EXIST.
DO $$
BEGIN
IF NOT EXISTS (SELECT 1 FROM pg_roles WHERE rolname = 'seer_user') THEN
CREATE ROLE seer_user;
END IF;
END
$$;
To view all roles: SELECT * FROM pg_roles;
SQL Server
sqlcmd -E
USE sahsuland;
IF DATABASE_PRINCIPAL_ID('seer_user') IS NULL
CREATE ROLE [seer_user];
ALTER ROLE [seer_user] ADD MEMBER [peter];
GO
To view all roles: SELECT name, type_desc FROM sys.database_principals;
Remote Database Access
The RIF supports SQL/MED SQL Management of External Data
Postgres with a remote Oracle database
The uses the Oracle foreign data wrapper with downloads for Windows at:
(https://github.com/laurenz/oracle_fdw/releases/tag/ORACLE_FDW_2_1_0).
On Windows you may get: ERROR: could not load library “C:/POSTGR~1/pg10/../pg10/lib/postgresql/oracle_fdw.dll”: The specified module could not
be found. There us a good article explaining what to do at: Cannot load oracle_fdw.dll under Windows Server 2012 R2 #160. The key
issue is the path:
- The Postgres bin directory: *C:\PostgreSQL\pg10\bin”;
- The extension folder: *C:\PostgreSQL\pg10\lib\postgresql”;
- The Oracle instant client directory (I choose: C:\Program Files\Oracle Instant Client\instantclient_18_3);
The local Postgres environment setup file C:\PostgreSQL\pg10\pg10-env.bat was changed from:
set PATH=C:\POSTGR~1\pg10\bin;%PATH%
To:
set PATH=C:\POSTGR~1\pg10\bin;C:\POSTGR~1\pg10\lib\postgresql;C:\PROGRA~1\ORACLE~1\INSTAN~1;%PATH%
The server was then restarted. Note that the path is in the old DOS format.
-
Create the extension as Postgres in the production database:
CREATE EXTENSION oracle_fdw;
-
Test extension. Note the Oracle instant client:
SELECT oracle_diag();
oracle_diag
-------------------------------------------------------------
oracle_fdw 2.1.0, PostgreSQL 10.5, Oracle client 18.3.0.0.0
(1 row)
-
Create a remote server and grant access to RIF users:
CREATE SERVER oradb FOREIGN DATA WRAPPER oracle_fdw
OPTIONS (dbserver '//dbserver.mydomain.com:1521/ORADB');
GRANT USAGE ON FOREIGN SERVER oradb TO rif_user, rif_manager;
-
Create a remote user. This will not normally be a schema owner:
CREATE USER MAPPING FOR peter SERVER oradb
OPTIONS (user 'orapeter', password 'oraretep');
-
Create a remote table link:
CREATE FOREIGN TABLE rif_data.oratab (
id integer OPTIONS (key 'true') NOT NULL,
text character varying(30),
floating double precision NOT NULL
) SERVER oradb OPTIONS (schema 'ORAUSER', table 'ORATAB');
- Test access:
SELECT FROM rif_data.oratab LIMIT 20;
- There is no need to grant access on the foreign table to specific users, the user mapping controls the access.
SQL Server with a remote Oracle database
- Requires the Oracle instant client (see Postgres);
- Download 64-bit Oracle Data Access Components (ODAC)
- Unzip the download and CD into its base, run
install.bat all c:\oracle odac
C:\>cd C:\Users\support\Downloads\ODAC122010Xcopy_x64
C:\Users\support\Downloads\ODAC122010Xcopy_x64>install.bat all c:\oracle odac
This installs in C:\oracle.
-
Check the Oracle OLEDB provider is picked up in SQL Server manager:
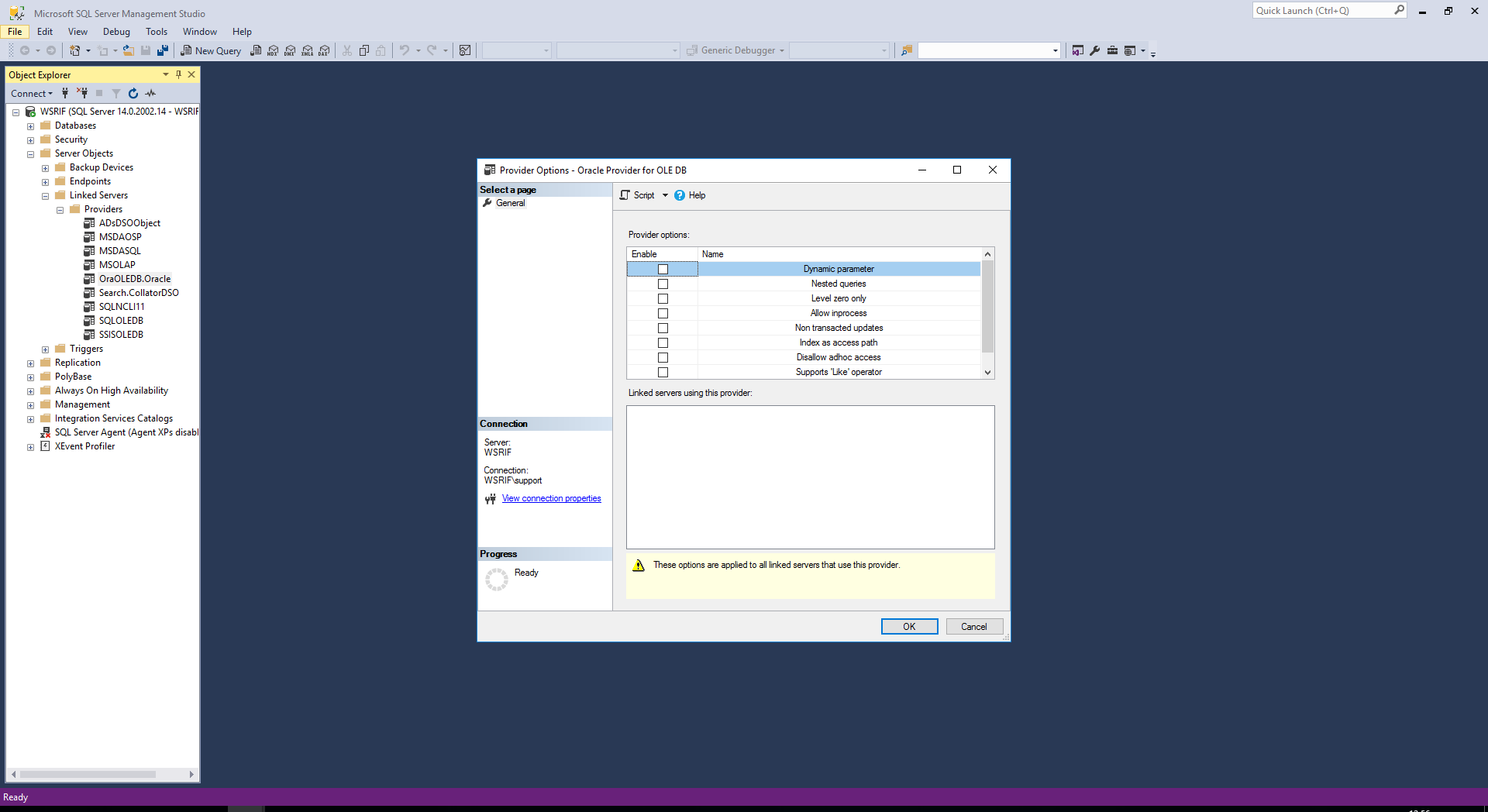
-
Create a remote link to the Oracle database. A schema account will be required:
https://www.sqlshack.com/link-sql-server-oracle-database/
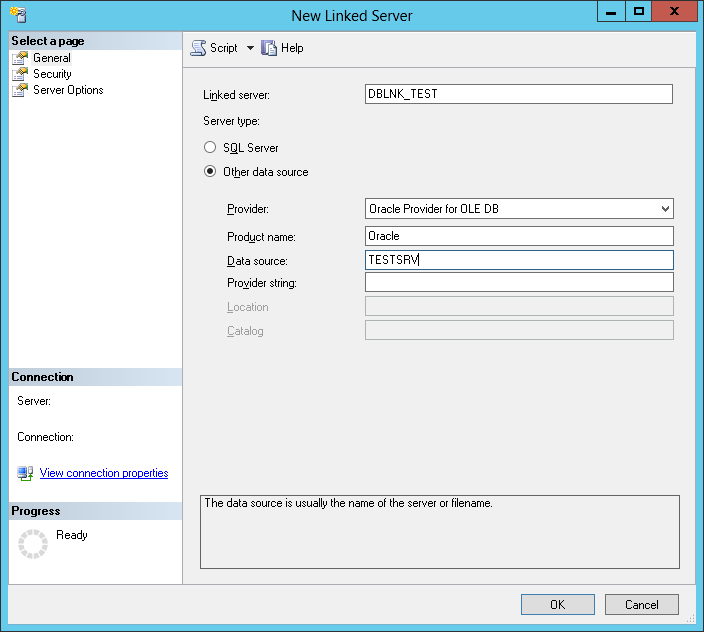
- Create a VIEW to the remote abject in the rif_data schema:
CREATE VIEW rif_data.msqltab AS
SELECT * FROM {remote_db].[remote_schema].[remote_table_or_view];
- Grant access to local user:
GRANT SELECT ON rif_data.msqltab TO peter;
- Test access:
SELECT TOP 20 FROM rif_data.msqltab;
Postgres with a remote SQL Server database
This requires TDS foreign data wrapper and is not currently compiled for Windows.
SQL Server with a remote Postgres database
This would require PostgreSQL OLE DB Provider project and is no longer under active
development (last version 1.0.20 from April 2006. There is a commercial driver available PGNP OLEDB Providers for PostgreSQL, Greenplum and Redshift
for $498. The PostgreSQL Global Development Group do not endorse or recommend any products listed, and cannot vouch for the
quality or reliability of any of them; and neither does SAHSU!
This currently covers:
Auditing
Postgres
Basic statement logging can be provided by the standard logging facility with the configuration parameter log_statement = all.
Postgres has an extension pgAudit which provides much more auditing, however the Enterprise DB installer does not include Postgres
extensions (apart from PostGIS). EnterpiseDB Postgres has its own auditing subsystem (*edb_audit), but this is is paid for item. To use pgAudit the module must be compile from source
To configure Postgres server error reporting and logging set the following Postgres system parameters see
Postgres tuning for details on how to set parameters:
log_statement = all. The default is ‘none’;Set log_min_error_statement = error [default] or lower;log_error_verbosity = verbose;log_connections = on;log_disconnections = on;log_destinstion = stderr, eventlog, csvlog. Other choices are csvlog or syslog*
Parameters can be set in the postgresql.conf file or on the server command line. This is stored in the database cluster’s data directory, e.g. C:\Program Files\PostgreSQL\9.6\data. Beware, you can
move the data directory to a solid state disk, mine is: E:\Postgres\data! Check the startup parameters in the Windows services app for the “-D” flag:
"C:\Program Files\PostgreSQL\9.6\bin\pg_ctl.exe" runservice -N "postgresql-x64-9.6" -D "E:\Postgres\data" -w
If you are using CSV log files set:
logging_collector = on;log_filename = postgresql-%Y-%m-%d.log and log_rotation_age = 1440 (in minutes) to provide a consistent, predictable naming scheme for your log files. This lets you predict what the file name will be and know
when an individual log file is complete and therefore ready to be imported. The log filename is in strftime() format;log_rotation_size = 0 to disable size-based log rotation, as it makes the log file name difficult to predict;log_truncate_on_rotation = on to on so that old log data isn’t mixed with the new in the same file.
Create a Postgres event log custom view, create a custom event view in the Event Viewer.
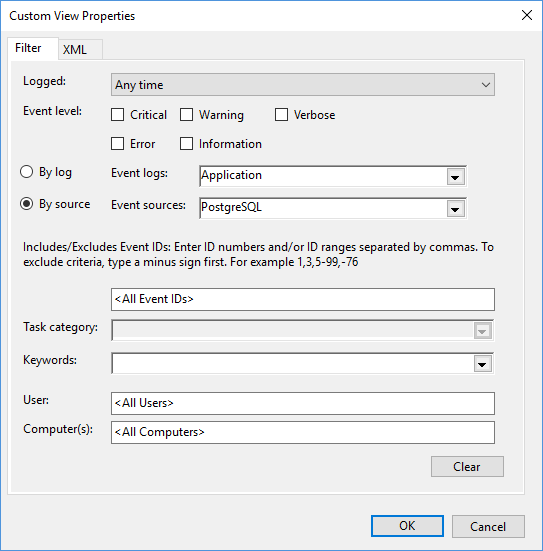
An XML setup file postgres_event_log_custom_view.xml
is also provided:
<ViewerConfig>
<QueryConfig>
<QueryParams>
<Simple>
<Channel>Application</Channel>
<RelativeTimeInfo>0</RelativeTimeInfo>
<Source>PostgreSQL</Source>
<BySource>True</BySource>
</Simple>
</QueryParams>
<QueryNode>
<Name>PostgreSQL</Name>
<Description>Postgres DB</Description>
<QueryList>
<Query Id="0" Path="Application">
<Select Path="Application">*[System[Provider[@Name='PostgreSQL']]]</Select>
</Query>
</QueryList>
</QueryNode>
</QueryConfig>
</ViewerConfig>
An example log file extract (postgresql-2018-05-21.log):
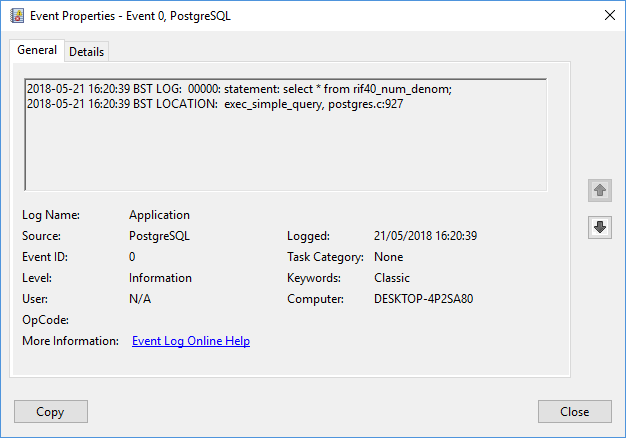
2018-05-21 16:20:39 BST LOG: 00000: statement: select * from rif40_num_denom;
2018-05-21 16:20:39 BST LOCATION: exec_simple_query, postgres.c:927
The equivalent CSV file entry (postgresql-2018-05-21.csv) is far more detailed:
2018-05-21 16:20:39.261 BST,"peter","sahsuland",9900,"::1:62022",5b02e3be.26ac,4,"",2018-05-21 16:20:30 BST,2/237,0,LOG,00000,"statement: select * from rif40_num_denom;",,,,,,,,"exec_simple_query, postgres.c:927","RIF (psql)"
2
By loading the CSV log in to a table it can then be queried:
CREATE TABLE postgres_log
(
log_time timestamp(3) with time zone,
user_name text,
database_name text,
process_id integer,
connection_from text,
session_id text,
session_line_num bigint,
command_tag text,
session_start_time timestamp with time zone,
virtual_transaction_id text,
transaction_id bigint,
error_severity text,
sql_state_code text,
message text,
detail text,
hint text,
internal_query text,
internal_query_pos integer,
context text,
query text,
query_pos integer,
location text,
application_name text,
PRIMARY KEY (session_id, session_line_num)
);
CREATE TABLE
\copy postgres_log FROM 'E:\Postgres\data\pg_log\postgresql-2018-05-21.csv' WITH csv;
COPY 25
sahsuland=> SELECT * FROM postgres_log WHERE user_name = USER AND message LIKE '%select * from rif40_num_denom;';
log_time | user_name | database_name | process_id | connection_from | session_id | session_line_num | command_tag | session_start_time | virtual_transaction_id | transaction_id | error_severity | sql_state_code | message | detail | hint | internal_query | internal_query_pos | context | query | query_pos | location | application_name
----------------------------+-----------+---------------+------------+-----------------+---------------+------------------+-------------+------------------------+------------------------+----------------+----------------+----------------+-------------------------------------------+--------+------+----------------+--------------------+---------+-------+-----------+-----------------------------------+------------------
2018-05-21 16:20:39.261+01 | peter | sahsuland | 9900 | ::1:62022 | 5b02e3be.26ac | 4 | | 2018-05-21 16:20:30+01 | 2/237 | 0 | LOG | 00000 | statement: select * from rif40_num_denom; | | | | | | | | exec_simple_query, postgres.c:927 | RIF (psql)
(1 row)
Formatted the CSV log entry is:
| Log field name |
Value |
| log_time |
2018-05-21 16:20:39.261+01 |
| user_name |
peter |
| database_name |
sahsuland |
| process_id |
9900 |
| connection_from |
::1:62022 |
| session_id |
5b02e3be.26ac |
| session_line_num |
4 |
| command_tag |
|
| session_start_time |
2018-05-21 16:20:30+01 |
| virtual_transaction_id |
2/237 |
| transaction_id |
0 |
| error_severity |
LOG |
| sql_state_code |
00000 |
| message |
statement: select * from rif40_num_denom; |
| detail |
|
| hint |
|
| internal_query |
|
| internal_query_pos |
|
| context |
|
| query |
|
| query_pos |
|
| location |
exec_simple_query, postgres.c:927 |
| application_name |
RIF (psql) |
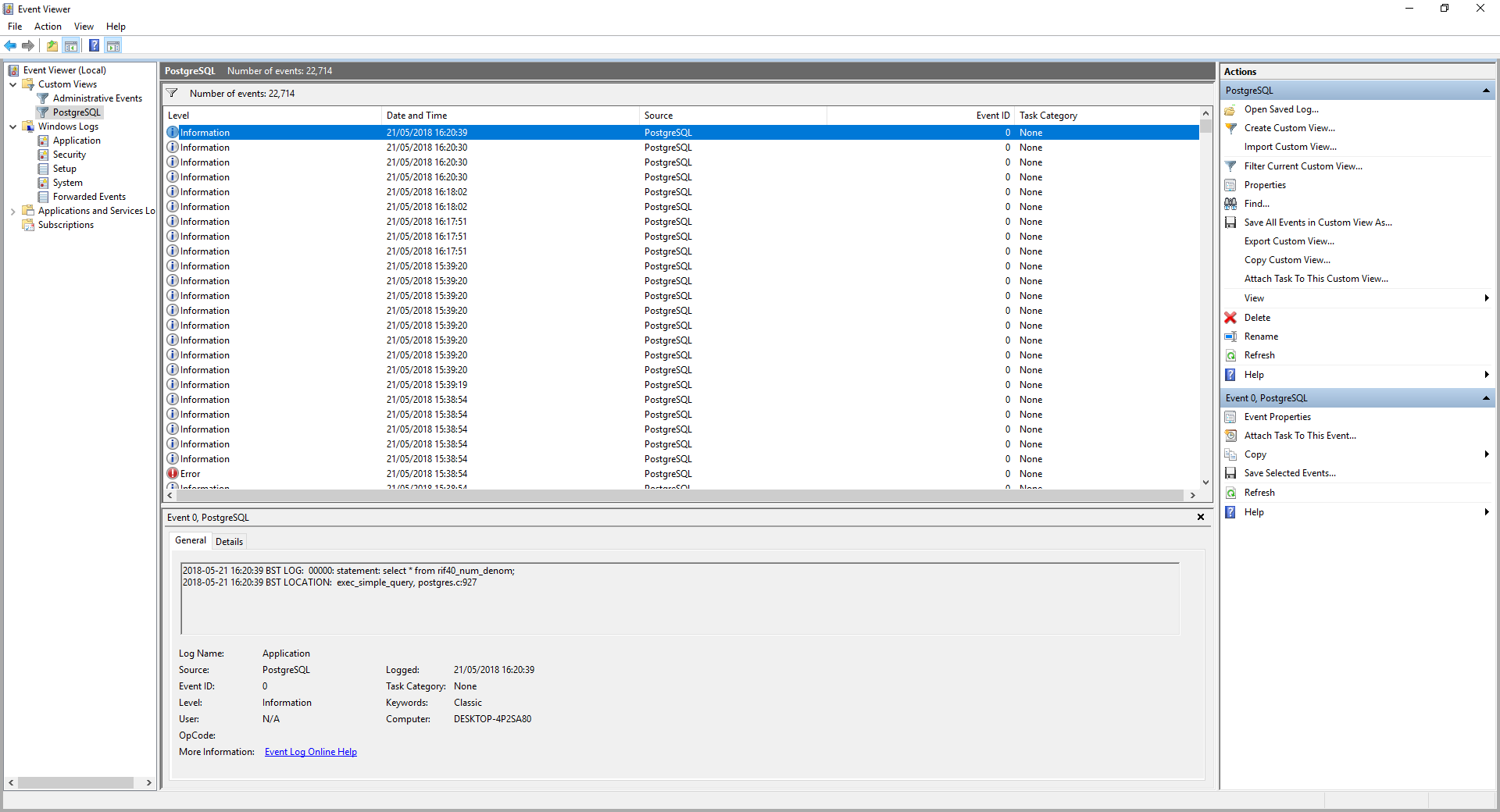
The equivalent PostgreSQL Windows log entry entry is:
SQL Server
See:
To setup (Common criteria compliance:
- Use the SQL Server management studio server properties pane:
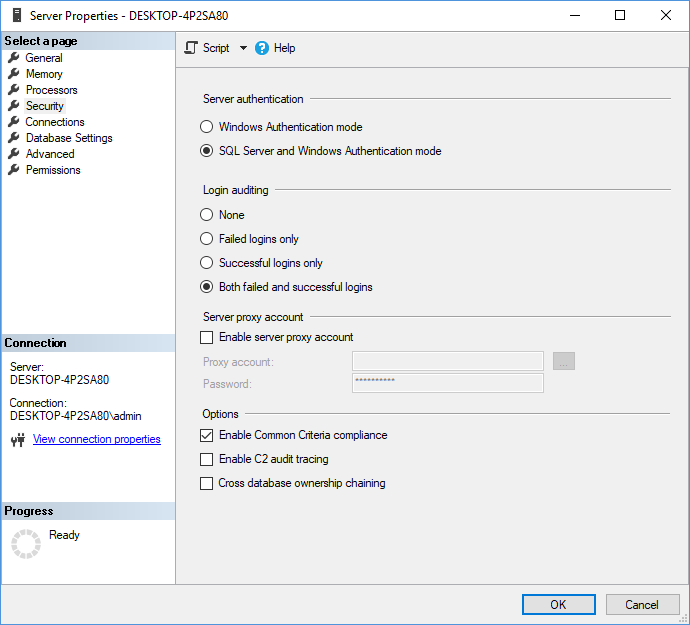
- Also check audit failed and successful logins;
- Restart SQL Server;
TO BE ADDED: auditing DDL and DML (without using triggers!)
Backup and recovery
As with all relational databases; cold backups are recommended as a baselines and should be carried out using your enterprise backup tools with the database down. Two further backup solutions are
suggested:
- Logical backups (recommended given the likely size of most RIF databses);
- Continuous archiving and point-in-time recovery (PITR) for more advanced sites;
Because of the fully transactional nature of both Postgres and SQL Server consistent logical backups can be run with users logged on, the database does not need to be put into a quiescent state.
Please bear in mind that continuous archiving and point-in-time recovery greatly expands the recovery options allowing for corruption repair and recovery from
object deletion incidents.
Replication is invariably very complex and is beyond the scope of this manual. It is recommended for very large sites with Postgres because of Postgres’ poor support for corruption
detection and repair.
Postgres
Logical Backups
Postgres logical backup and recovery uses pg_dump and pg_restore. pg_dump only dumps a single database. To backup global objects that are common to all databases in a cluster, such as roles and tablespaces,
use pg_dumpall.
Two basic formats: 1) a SQL script to recreate the database using psql and 2) a binary dump file to restore using pg_restore.
- SQL Script:
pg_dump -U postgres -w -F plain -v -C sahsuland > sahsuland.sql
- Binary dump file:
pg_dump -U postgres -w -F custom -v sahsuland > sahsuland.dump
Where the database name is sahsuland.
Flags:
- -U postgres:
- -F <format%gt;: dump format: plain (SQL), custom or directory (pg_restore);
- -w: do not prompt for a password;
- -v: be verbose;
To restore a custom or directory pg_dump file: pg_restore -d sahsuland -U postgres -v sahsuland.dump. This is the method uses to create the example database sahsuland
from the development database sahsuland_dev. See:
Continuous Archiving and Point-in-Time Recovery
Postgres supports continuous archiving and point-in-time recovery (PITR). See:
SQL Server
Logical Backups
SQL Server logical backup and restore are SQL commands entered using sqlcmd. See:
BACKUP DATABASE [sahsuland] TO DISK='C:\Users\Peter\Documents\GitHub\rapidInquiryFacility\rifDatabase\SQLserver\installation\..\production\sahsuland.bak'
WITH COPY_ONLY, INIT;
GO
Msg 4035, Level 0, State 1, Server PETER-PC\SAHSU, Line 6
Processed 42040 pages for database 'sahsuland_dev', file 'sahsuland_dev' on file 54.
Msg 4035, Level 0, State 1, Server PETER-PC\SAHSU, Line 6
Processed 2 pages for database 'sahsuland_dev', file 'sahsuland_dev_log' on file 54.
Msg 3014, Level 0, State 1, Server PETER-PC\SAHSU, Line 6
BACKUP DATABASE successfully processed 42042 pages in 3.940 seconds (83.363 MB/sec).
To restore a backup:
RESTORE DATABASE [sahsuland]
FROM DISK='C:\Users\Peter\Documents\GitHub\rapidInquiryFacility\rifDatabase\SQLserver\installation\..\production\sahsuland.bak'
WITH REPLACE;
Msg 4035, Level 0, State 1, Server PETER-PC\SAHSU, Line 1
Processed 45648 pages for database 'sahsuland', file 'sahsuland' on file 1.
Msg 4035, Level 0, State 1, Server PETER-PC\SAHSU, Line 1
Processed 14 pages for database 'sahsuland', file 'sahsuland_log' on file 1.
Msg 3014, Level 0, State 1, Server PETER-PC\SAHSU, Line 1
RESTORE DATABASE successfully processed 45662 pages in 5.130 seconds (69.538 MB/sec).
See the script rif40_production_creation.sql if you want to rename the database, its files or to move the files.
Continuous Archiving and Point-in-Time Recovery
This requires a transaction log backup, i.e. not the copy only version created in the previous section. You will need to do a full backup, followed by differential backups:
-- Create a full database backup first.
BACKUP DATABASE sahsuland
TO sahsuland
WITH INIT;
GO
-- Time elapses.
-- Create a differential database backup, appending the backup
-- to the backup device containing the full database backup.
BACKUP DATABASE sahsuland
TO sahsuland
WITH DIFFERENTIAL;
GO
Log backups require the database to be in the full recovery model, not the default simple recovery model. See:
Back Up a Transaction Log
For restoration see:
Restore a SQL Server Database to a Point in Time (Full Recovery Model
Patching
Alter scripts are numbered sequentially and have the same functionality in both ports, e.g. v4_0_alter_10.sql. Scripts are safe to run more than once.
Pre-built databases are supplied patched up to date.
Scripts must be applied as follows:
| Date |
Script |
Description |
| 3rd August 2018 |
v4_0_alter_10.sql |
Risk analysis changes |
| 13th October 2018 |
v4_0_alter_11.sql |
Risk analysis changes |
You will get messages on logon such as alter_10.sql (post 3rd August 2018 changes for risk analysis) not run to tell you to run the alter scripts.
Postgres
E.g. for alter 10:
- Working directory: …rapidInquiryFacility/rifDatabase/Postgres/psql_scripts
- Run:
psql -U rif40 -d sahsuland -w -e -P pager=off -f alter_scripts/v4_0_alter_10.sql
Alter scripts v4_0_alter_1.sql to v4_0_alter_9.sql related to be original database development on Postgres
and were not created on SQL Server. The scripts v4_0_alter_3.sql and v4_0_alter_4.sql enable partitioning by
ranges (data with year fields) and hashes (study_id) respectively. Alter script 4 must go after 7. Alter
script 7 provides:
- Support for ontologies (e.g. ICD9, 10); removed previous table based support.
- Modify t_rif40_inv_conditions to remove SQL injection risk
This is because alter script 7 was written before the partitioning was enabled and does not support it.
Partitioning was removed as it is supported natively in Postgres 10. Support for hash partitioning is
in alter 4 and is incomplete:
- Partition movement is not supported;
- The hashing function rif40_sql_pkg._rif40_hash has not been added to the code so hash partition elimination
will not occur. Range partition elimination does work.
CREATE OR REPLACE FUNCTION rif40_sql_pkg._rif40_hash(l_value VARCHAR, l_bucket INTEGER)
RETURNS INTEGER
AS 'SELECT (ABS(hashtext(l_value))%l_bucket)+1;' LANGUAGE sql IMMUTABLE STRICT;
The actual partitioning is carried out by: v4_0_study_id_partitions.sql and v4_0_year_partitions.sql and
the rif40_sql_pkg.rif40_hash_partition and rif40_sql_pkg.rif40_range_partition packages.
This code has not been used since early 2018 and is supplied as is with testing since that date. RIF users
are strongly advised to use the native Postgres 10 functionality.
Scripts are in the standard bundle in the directory Database alter scripts\Postgres or in github in rapidInquiryFacility\rifDatabase\Postgres\psql_scripts\alter_scripts
psql -U rif40 -d <your database name> -w -e -P pager=off -v verbosity=terse -v debug_level=0 -v use_plr=N -v pghost=localhost -v echo=none -f alter_scripts/<alter script name>
SQL Server
Scripts are in the standard bundle in the directory Database alter scripts\SQL Server or in github in rapidInquiryFacility\rifDatabase\SQLserver\sahsuland_dev\alter_scripts
sqlcmd -U rif40 -P <rif40 password> -d <your database name> -b -m-1 -e -r1 -i <alter script name>
E.g. for alter 10:
- Working directory: …rapidInquiryFacility/rifDatabase/SQLserver/alter scripts
- Run:
sqlcmd -U rif40 -d <database name> -b -m-1 -e -r1 -i v4_0_alter_10.sql -v pwd="%cd%"
- Connect flags if required: -P -S
Tuning
The following aspects of tuning are covered:
- Server memory allocation
- Huge/large page support
- RIF application tuning
In general RIF database performance will benefit from:
- Complete partitioning of all health, population and covariate data;
- Allowing the use of limited parallelisation in queries, inserts and index creation;
- Use of index organised denominator and covariate tables. Note that by default all tables are index organised on SQL Server;
See Partitioning
Postgres
Server Memory Tuning
The best source for Postgres tuning information is at the Postgres Performance Optimization Wiki. This references
Tuning Your PostgreSQL Server
Parameters can be set in the postgresql.conf file or on the server command line. This is stored in the database cluster’s data directory, e.g. C:\Program Files\PostgreSQL\9.6\data. Beware, you can
move the data directory to a solid state disk, mine is: * E:\Postgres\data! Check the startup parameters in the Windows services app for the *“-D” flag:
"C:\Program Files\PostgreSQL\9.6\bin\pg_ctl.exe" runservice -N "postgresql-x64-9.6" -D "E:\Postgres\data" -w
An example postgresql.conf is supplied.
The principal tuning changes are:
- Shared buffers: 1GB. Can be tuned higher if required (see below);
- Temporary buffers: 1-4GB
- Work memory: 1GB. The Maximum is 2047MB;
- Effective_cache_size: 1/2 of total memory
-
On Linux try to use huge pages. This is called large page support in Windows and is not yet implemented (it was committed on
21st January 2018 and should appear in Postgres 11 scheduled for Q3 2018). This is to reduce the process memory footprint
Physical and Virtual Memory in Windows 10 by Sushovon Sinha: translation lookaside buffer
size. Query “windows translation lookaside buffer” in Google if Microsoft moves this link again!!
Example parameter entries from postgresql.conf:
shared_buffers = 1024MB # min 128kB; default 128 MB (9.6)
# (change requires restart)
temp_buffers = 1G # min 800kB; default 8M
huge_pages = try # on, off, or try: Linux only
# (change requires restart)
work_mem = 1GB # min 64kB; default 4MB
log_temp_files = 5000 # log temporary files equal or larger [5MB]
# than the specified size in kilobytes;
# -1 disables [default], 0 logs all temp files
# From "Tuning Your PostgreSQL Server": Setting effective_cache_size to 1/2 of total memory would be a normal conservative setting,
# and 3/4 of memory is a more aggressive but still reasonable amount.
#effective_cache_size = 4GB
effective_cache_size = 20GB
On Windows, I modified the postgresql.conf rather than use SQL at the server command line. This is because the server command line needs to be in the units of the parameters,
so shared buffers of 1G is 131072 8KB pages. This is not very intuitive compared to using MB/GB etc.
The amount of memory given to Postgres should allow room for tomcat if installed together with the application server; shared memory should generally not exceed a quarter of the available RAM.
Tuning the buffer cache, see: A Large Database Does Not Mean Large shared_buffers. Add the
pg_buffercache extension as the postgres user: CREATE EXTENSION pg_buffercache;, then run the following query as postgres:
When running these queries, please bear in mind that shared_buffers usage varies with the type of workload;
data loading (especially geospatial) will generally hit a few large tables often; normal RIF usage which is
more OLTP like less so. There run these queries often under different loads.
Firstly see how many buffers are in use by database:
SELECT CASE
WHEN d.datname = current_database() THEN d.datname || ' (current)'
ELSE d.datname
END AS database,
ROUND(100.0 * COUNT(*) / ( SELECT setting FROM pg_settings WHERE name='shared_buffers')::integer,3) AS buffers_in_use_percent
FROM pg_buffercache b, pg_database d
WHERE b.reldatabase = d.oid
GROUP BY CASE
WHEN d.datname = current_database() THEN d.datname || ' (current)'
ELSE d.datname
END
ORDER BY 1;
database | buffers_in_use_percent
-------------------------+------------------------
sahsuland_dev (current) | 99.988
(1 row)
This is across all databases. 100% is not unusual, much less than 100% probably means your shared_buffers are
too large (unless the other databases are doing substantial work).
Now see what is being used in the current database:
SELECT n.nspname AS "schema",
c.relname AS "table name",
c2.relname AS "toast table",
c3.relname AS "primary table",
pg_size_pretty(COUNT(*) * ( SELECT setting FROM pg_settings WHERE name = 'block_size')::INTEGER) AS buffered,
ROUND(100.0 * COUNT(*) / ( SELECT setting FROM pg_settings WHERE name='shared_buffers')::INTEGER,3) AS "buffers percent",
ROUND(100.0 * COUNT(*) * ( SELECT setting FROM pg_settings WHERE name = 'block_size')::INTEGER / pg_relation_size(c.oid),1) AS "percent of relation",
b.usagecount AS "usage count"
FROM pg_class c
INNER JOIN pg_buffercache b ON b.relfilenode = c.relfilenode
INNER JOIN pg_database d ON (b.reldatabase = d.oid AND d.datname = current_database()) /* Restrict to current database */
INNER JOIN pg_namespace n ON n.oid = c.relnamespace
LEFT OUTER JOIN pg_class c2 ON c2.oid = c.reltoastrelid
LEFT OUTER JOIN pg_class c3 ON c3.oid =
CASE
WHEN REPLACE(REPLACE(c.relname, 'pg_toast_', ''), '_index', '') ~ '^[0-9]+$' THEN REPLACE(REPLACE(c.relname, 'pg_toast_', ''), '_index', '')::oid
ELSE NULL
END
WHERE pg_relation_size(c.oid) > 0 /* Exclude non table objects or zero sized objects */
AND ((c.relname NOT LIKE 'pg_%' OR c.relname LIKE 'pg_toast_%') /* Exclude data dictionary but not TOAST tables */)
AND (c3.relname IS NULL OR c3.relname NOT LIKE 'pg_%' /* Exclude data dictionary but not TOAST tables */)
GROUP BY c.oid, n.nspname, c.relname, c2.relname, c3.relname, b.usagecount
ORDER BY 6 DESC;
This gives the following output here the columns are:
- schema: Schema;
- table name: Table;
- toast table: TOAST (The Oversized-Attribute Storage Technique) table;
- primary table: primary table associated with TOAST (The Oversized-Attribute Storage Technique) table;
- buffered: Amount of table cached in shared_buffers;
- buffers percent: % of shared_buffers use by this table;
- percent of relation: % of table buffered;
- usage count: times used by separate queries (can be the same SQL statement);
schema | table name | toast table | primary table | buffered | buffers percent | percent of relation | usage count
----------+------------------------+------------------+---------------+------------+-----------------+---------------------+-------------
pg_toast | pg_toast_1983440 | | coa2011 | 9672 kB | 0.922 | 0.6 | 5
peter | coa2011_geom_orig_gix | | | 9664 kB | 0.922 | 71.3 | 2
pg_toast | pg_toast_3163099 | | gor2011 | 95 MB | 9.316 | 100.0 | 5
rif40 | t_rif40_parameters | | | 8192 bytes | 0.001 | 100.0 | 3
rif40 | t_rif40_parameters_pk | | | 8192 bytes | 0.001 | 50.0 | 1
public | spatial_ref_sys | pg_toast_321436 | | 8192 bytes | 0.001 | 0.2 | 2
public | spatial_ref_sys | pg_toast_321436 | | 8192 bytes | 0.001 | 0.2 | 5
public | spatial_ref_sys_pkey | | | 8192 bytes | 0.001 | 4.2 | 2
peter | coa2011 | pg_toast_1983440 | | 8192 bytes | 0.001 | 0.0 | 4
peter | gor2011 | pg_toast_3163099 | | 8192 bytes | 0.001 | 100.0 | 5
pg_toast | pg_toast_3163099 | | gor2011 | 8192 bytes | 0.001 | 0.0 | 2
peter | gor2011_pkey | | | 8192 bytes | 0.001 | 50.0 | 1
peter | gor2011_uk | | | 8192 bytes | 0.001 | 50.0 | 1
pg_toast | pg_toast_1983440 | | coa2011 | 8000 kB | 0.763 | 0.5 | 0
peter | coa2011_geom_8_gix | | | 7048 kB | 0.672 | 54.1 | 0
pg_toast | pg_toast_1983440_index | | coa2011 | 656 kB | 0.063 | 1.9 | 5
peter | coa2011_geom_9_gix | | | 6264 kB | 0.597 | 46.1 | 2
peter | coa2011_geom_9_gix | | | 5912 kB | 0.564 | 43.5 | 1
peter | coa2011 | pg_toast_1983440 | | 532 MB | 51.966 | 19.4 | 1
peter | coa2011_geom_7_gix | | | 5040 kB | 0.481 | 39.3 | 0
peter | coa2011_geom_8_gix | | | 4832 kB | 0.461 | 37.1 | 1
peter | coa2011 | pg_toast_1983440 | | 40 kB | 0.004 | 0.0 | 2
pg_toast | pg_toast_1983440_index | | coa2011 | 2528 kB | 0.241 | 7.3 | 4
pg_toast | pg_toast_1983440 | | coa2011 | 25 MB | 2.437 | 1.5 | 3
peter | coa2011_geom_orig_gix | | | 2488 kB | 0.237 | 18.4 | 3
peter | coa2011 | pg_toast_1983440 | | 24 kB | 0.002 | 0.0 | 3
pg_toast | pg_toast_1983440 | | coa2011 | 2344 kB | 0.224 | 0.1 | 1
pg_toast | pg_toast_1983440 | | coa2011 | 208 kB | 0.020 | 0.0 | 2
peter | coa2011_geom_orig_gix | | | 192 kB | 0.018 | 1.4 | 0
peter | coa2011_geom_orig_gix | | | 184 kB | 0.018 | 1.4 | 1
peter | coa2011 | pg_toast_1983440 | | 170 MB | 16.640 | 6.2 | 0
peter | coa2011 | pg_toast_1983440 | | 160 kB | 0.015 | 0.0 | 5
public | spatial_ref_sys_pkey | | | 16 kB | 0.002 | 8.3 | 5
peter | coa2011_geom_9_gix | | | 152 kB | 0.014 | 1.1 | 0
pg_toast | pg_toast_1983440 | | coa2011 | 130 MB | 12.648 | 7.8 | 4
pg_toast | pg_toast_3163099_index | | gor2011 | 1088 kB | 0.104 | 100.0 | 5
(36 rows)
Note the use of TOAST tables in Postgres.
TOAST (The Oversized-Attribute Storage Technique) is used to store large field values,
for instance the geometry databases on cntry2011 as in this example.
Now it is possible to determine an ideal value for shared_buffers:
SELECT CASE
WHEN d.datname = current_database() THEN d.datname || ' (current)'
ELSE d.datname
END AS database,
CASE
WHEN usagecount >3 THEN '>3'
ELSE ' '||usagecount::Text END AS usagecount,
pg_size_pretty(count(*) * ( SELECT setting FROM pg_settings WHERE name = 'block_size')::INTEGER) as ideal_shared_buffers
FROM pg_class c
INNER JOIN pg_buffercache b ON b.relfilenode = c.relfilenode
INNER JOIN pg_database d ON (b.reldatabase = d.oid)
GROUP BY CASE
WHEN d.datname = current_database() THEN d.datname || ' (current)'
ELSE d.datname
END,
CASE
WHEN usagecount >3 THEN '>3'
ELSE ' '||usagecount::Text END
ORDER BY 1, 2 DESC;
A usage count of:
- 1: this is the system caching all data;
- 2,3: occasional caching;
- >3: suitable target for shared_buffer;
If you wanted to cache everything with a usagecount of 2 you would need to add the >3, 3 and 2 figures together!
database | usagecount | ideal_shared_buffers
-------------------------+------------+----------------------
sahsuland_dev (current) | >3 | 485 MB
sahsuland_dev (current) | 3 | 353 MB
sahsuland_dev (current) | 2 | 86 MB
sahsuland_dev (current) | 1 | 44 MB
sahsuland_dev (current) | 0 | 55 MB
(5 rows)
This should give a reasonable starting performance on an OLTP system.
You will need to run this many times under different loads to determine a suitable value. In this case a
1GB cache appears to be fine for the geospatial workload. Note however that the shared_buffers are 100% used.
The problem with just looking at the buffer cache is it does not tell you what effect cache misses are having on performance.
WITH all_tables AS (
SELECT *
FROM (
SELECT 'All'::Text AS schema_name, 'ALL'::text AS table_name,
'N/A'::Text AS toast_table, 'N/A'::Text AS primary_table,
SUM( (coalesce(heap_blks_read,0) + coalesce(idx_blks_read,0) + coalesce(toast_blks_read,0) + coalesce(tidx_blks_read,0)) ) AS from_disk,
SUM( (coalesce(heap_blks_hit,0) + coalesce(idx_blks_hit,0) + coalesce(toast_blks_hit,0) + coalesce(tidx_blks_hit,0)) ) AS from_cache,
(SELECT pg_size_pretty(COUNT(*) * ( SELECT setting FROM pg_settings WHERE name = 'block_size')::INTEGER) AS buffered
FROM pg_buffercache b, pg_database d
WHERE b.reldatabase = d.oid
AND d.datname = current_database()) AS buffered
FROM pg_statio_all_tables --> change to pg_statio_USER_tables if you want to check only user tables (excluding postgres's own tables)
) a
WHERE (from_disk + from_cache) > 0 -- discard tables without hits
), tables AS (
SELECT a.schemaname AS schema_name, a.relname AS table_name,
c2.relname AS toast_table, c3.relname AS primary_table,
a.from_disk, a.from_cache,
pg_size_pretty(COUNT(b.relfilenode) * ( SELECT setting FROM pg_settings WHERE name = 'block_size')::INTEGER) AS buffered
FROM (
SELECT c.*, s.schemaname, s.from_disk, s.from_cache
FROM (
SELECT relid, schemaname,
( (coalesce(heap_blks_read,0) + coalesce(idx_blks_read,0) + coalesce(toast_blks_read,0) + coalesce(tidx_blks_read,0)) ) AS from_disk,
( (coalesce(heap_blks_hit,0) + coalesce(idx_blks_hit,0) + coalesce(toast_blks_hit,0) + coalesce(tidx_blks_hit,0)) ) AS from_cache
FROM pg_statio_all_tables --> change to pg_statio_USER_tables if you want to check only user tables (excluding postgres's own tables)
) s, pg_class c WHERE c.oid = s.relid
) a
LEFT OUTER JOIN pg_buffercache b ON b.relfilenode = a.relfilenode
LEFT OUTER JOIN pg_class c2 ON c2.oid = a.reltoastrelid
LEFT OUTER JOIN pg_class c3 ON c3.oid =
CASE
WHEN REPLACE(REPLACE(a.relname, 'pg_toast_', ''), '_index', '') ~ '^[0-9]+$' THEN
REPLACE(REPLACE(a.relname, 'pg_toast_', ''), '_index', '')::oid
ELSE NULL
END
WHERE ((a.relname NOT LIKE 'pg_%' OR a.relname LIKE 'pg_toast_%') /* Exclude data dictionary but not TOAST tables */)
AND (c3.relname IS NULL OR c3.relname NOT LIKE 'pg_%' /* Exclude data dictionary but not TOAST tables */)
AND (a.from_disk + a.from_cache) > 0 -- discard tables without hits
GROUP BY a.schemaname, a.relname,
c2.relname, c3.relname,
a.from_disk, a.from_cache
)
SELECT schema_name AS "schema name",
table_name AS "table name",
toast_table AS "toast table",
primary_table AS "primary table",
from_disk AS "disk hits",
round((from_disk::numeric / (from_disk + from_cache)::numeric)*100.0,2) AS "% disk hits",
round((from_cache::numeric / (from_disk + from_cache)::numeric)*100.0,2) AS "% cache hits",
(from_disk + from_cache) AS "total hits",
buffered AS "buffered"
FROM (SELECT * FROM all_tables UNION ALL SELECT * FROM tables) a
ORDER BY (CASE WHEN table_name = 'ALL' THEN 0 ELSE 1 END), from_disk DESC;
Where the columns are:
- schema name: Schema;
- table name: Table;
- toast table: TOAST (The Oversized-Attribute Storage Technique) table;
- primary table: primary table associated with TOAST (The Oversized-Attribute Storage Technique) table;
- disk hits: Total hits on table from the disk;
- % disk hits: % of disk hits. Ideally this should be <10%;
- % cache hits: % of cache hits. Ideally this should be >90%;
- total hits: Total hits on table from the shared_buffers cache and disk;
- buffered: Amount of table cached in shared_buffers.
schema name | table name | toast table | primary table | disk hits | % disk hits | % cache hits | total hits | buffered
-------------+---------------------------------------------------+------------------+---------------------------------------------------+-----------+-------------+--------------+------------+------------
All | ALL | N/A | N/A | 11655875 | 4.25 | 95.75 | 274207672 | 1024 MB
peter | coa2011 | pg_toast_3523190 | | 7869405 | 6.49 | 93.51 | 121248197 | 0 bytes
peter | lsoa2011 | pg_toast_4708439 | | 1224683 | 2.27 | 97.73 | 53923473 | 0 bytes
pg_toast | pg_toast_3523190 | | coa2011 | 715589 | 3.69 | 96.31 | 19405252 | 0 bytes
pg_toast | pg_toast_4708439 | | lsoa2011 | 321707 | 3.24 | 96.76 | 9932869 | 0 bytes
peter | geometry_ews2011_geolevel_id_7_zoomlevel_9 | pg_toast_5055911 | | 172584 | 2.76 | 97.24 | 6245362 | 0 bytes
peter | geometry_ews2011_geolevel_id_7_zoomlevel_8 | pg_toast_5055901 | | 168785 | 12.41 | 87.59 | 1359723 | 0 bytes
peter | geometry_ews2011_geolevel_id_7_zoomlevel_7 | pg_toast_5055891 | | 141985 | 11.44 | 88.56 | 1240941 | 0 bytes
peter | msoa2011 | pg_toast_4976604 | | 133320 | 0.60 | 99.40 | 22268185 | 0 bytes
peter | geometry_ews2011_geolevel_id_7_zoomlevel_6 | pg_toast_5055881 | | 122665 | 10.16 | 89.84 | 1207286 | 117 MB
peter | geometry_ews2011_geolevel_id_6_zoomlevel_9 | pg_toast_5055871 | | 97517 | 2.64 | 97.36 | 3697067 | 89 MB
pg_toast | pg_toast_4976604 | | msoa2011 | 95295 | 2.00 | 98.00 | 4765263 | 0 bytes
peter | geometry_ews2011_geolevel_id_6_zoomlevel_8 | pg_toast_5055861 | | 68563 | 17.23 | 82.77 | 397843 | 0 bytes
peter | tile_intersects_ews2011_geolevel_id_7_zoomlevel_0 | pg_toast_5071372 | | 57432 | 2.81 | 97.19 | 2046639 | 0 bytes
peter | geometry_ews2011_geolevel_id_6_zoomlevel_7 | pg_toast_5055851 | | 51025 | 16.32 | 83.68 | 312694 | 0 bytes
peter | geometry_ews2011_geolevel_id_6_zoomlevel_6 | pg_toast_5055841 | | 40263 | 14.86 | 85.14 | 270952 | 0 bytes
peter | ladua2011 | pg_toast_4703093 | | 28762 | 1.14 | 98.86 | 2531926 | 0 bytes
peter | geometry_ews2011_geolevel_id_5_zoomlevel_9 | pg_toast_5055831 | | 28192 | 1.20 | 98.80 | 2351736 | 0 bytes
peter | tile_intersects_ews2011_geolevel_id_6_zoomlevel_0 | pg_toast_5071212 | | 26397 | 4.73 | 95.27 | 558081 | 0 bytes
peter | gor2011 | pg_toast_4702848 | | 25962 | 1.46 | 98.54 | 1784083 | 0 bytes
pg_toast | pg_toast_4703093 | | ladua2011 | 24773 | 3.16 | 96.84 | 783986 | 0 bytes
pg_toast | pg_toast_4702848 | | gor2011 | 23952 | 3.54 | 96.46 | 676983 | 0 bytes
peter | geometry_ews2011_geolevel_id_5_zoomlevel_8 | pg_toast_5055821 | | 18342 | 9.57 | 90.43 | 191641 | 0 bytes
peter | geometry_ews2011_geolevel_id_5_zoomlevel_6 | pg_toast_5055801 | | 15644 | 12.19 | 87.81 | 128319 | 0 bytes
peter | geometry_ews2011_geolevel_id_5_zoomlevel_7 | pg_toast_5055811 | | 15374 | 10.58 | 89.42 | 145371 | 0 bytes
peter | hierarchy_ews2011 | pg_toast_5055579 | | 15239 | 0.34 | 99.66 | 4437162 | 0 bytes
pg_toast | pg_toast_5055871 | | geometry_ews2011_geolevel_id_6_zoomlevel_9 | 12780 | 1.99 | 98.01 | 643402 | 29 MB
pg_toast | pg_toast_5055911 | | geometry_ews2011_geolevel_id_7_zoomlevel_9 | 12291 | 2.04 | 97.96 | 601709 | 0 bytes
pg_toast | pg_toast_5055831 | | geometry_ews2011_geolevel_id_5_zoomlevel_9 | 9274 | 2.11 | 97.89 | 439525 | 0 bytes
peter | tile_intersects_ews2011_geolevel_id_5_zoomlevel_0 | pg_toast_5071052 | | 8742 | 3.53 | 96.47 | 247448 | 0 bytes
pg_toast | pg_toast_5071372 | | tile_intersects_ews2011_geolevel_id_7_zoomlevel_0 | 8684 | 4.14 | 95.86 | 209511 | 0 bytes
pg_toast | pg_toast_5071212 | | tile_intersects_ews2011_geolevel_id_6_zoomlevel_0 | 7927 | 4.53 | 95.47 | 175020 | 0 bytes
pg_toast | pg_toast_5071052 | | tile_intersects_ews2011_geolevel_id_5_zoomlevel_0 | 5776 | 4.78 | 95.22 | 120758 | 0 bytes
peter | lookup_coa2011 | pg_toast_5055571 | | 5034 | 0.59 | 99.41 | 857506 | 0 bytes
peter | adjacency_ews2011 | pg_toast_5070504 | | 4855 | 0.46 | 99.54 | 1055413 | 0 bytes
pg_toast | pg_toast_5055861 | | geometry_ews2011_geolevel_id_6_zoomlevel_8 | 4588 | 6.73 | 93.27 | 68173 | 0 bytes
peter | geometry_ews2011_geolevel_id_4_zoomlevel_9 | pg_toast_5055791 | | 3440 | 0.30 | 99.70 | 1164684 | 0 bytes
peter | geometry_ews2011_geolevel_id_3_zoomlevel_9 | pg_toast_5055751 | | 3232 | 0.51 | 99.49 | 629888 | 0 bytes
pg_toast | pg_toast_5055751 | | geometry_ews2011_geolevel_id_3_zoomlevel_9 | 3182 | 5.31 | 94.69 | 59959 | 0 bytes
pg_toast | pg_toast_5055791 | | geometry_ews2011_geolevel_id_4_zoomlevel_9 | 3079 | 3.09 | 96.91 | 99728 | 0 bytes
pg_toast | pg_toast_5055901 | | geometry_ews2011_geolevel_id_7_zoomlevel_8 | 3033 | 8.62 | 91.38 | 35194 | 0 bytes
pg_toast | pg_toast_5055821 | | geometry_ews2011_geolevel_id_5_zoomlevel_8 | 3029 | 3.97 | 96.03 | 76312 | 0 bytes
peter | scntry2011 | pg_toast_5055439 | | 2527 | 2.00 | 98.00 | 126143 | 0 bytes
peter | cntry2011 | pg_toast_3523103 | | 2488 | 1.77 | 98.23 | 140612 | 0 bytes
pg_toast | pg_toast_5055439 | | scntry2011 | 2322 | 5.70 | 94.30 | 40749 | 0 bytes
pg_toast | pg_toast_3523103 | | cntry2011 | 2297 | 4.90 | 95.10 | 46845 | 0 bytes
pg_toast | pg_toast_5055801 | | geometry_ews2011_geolevel_id_5_zoomlevel_6 | 2279 | 5.74 | 94.26 | 39708 | 0 bytes
pg_toast | pg_toast_5055811 | | geometry_ews2011_geolevel_id_5_zoomlevel_7 | 1904 | 3.84 | 96.16 | 49525 | 0 bytes
peter | geometry_ews2011_geolevel_id_4_zoomlevel_6 | pg_toast_5055761 | | 1884 | 6.64 | 93.36 | 28370 | 0 bytes
peter | tile_intersects_ews2011_geolevel_id_4_zoomlevel_0 | pg_toast_5070892 | | 1700 | 4.06 | 95.94 | 41888 | 0 bytes
peter | tile_intersects_ews2011_geolevel_id_3_zoomlevel_0 | pg_toast_5070732 | | 1576 | 4.54 | 95.46 | 34750 | 0 bytes
pg_toast | pg_toast_5070732 | | tile_intersects_ews2011_geolevel_id_3_zoomlevel_0 | 1554 | 6.83 | 93.17 | 22764 | 0 bytes
peter | geometry_ews2011_geolevel_id_4_zoomlevel_8 | pg_toast_5055781 | | 1507 | 3.92 | 96.08 | 38431 | 0 bytes
pg_toast | pg_toast_5070892 | | tile_intersects_ews2011_geolevel_id_4_zoomlevel_0 | 1485 | 5.69 | 94.31 | 26095 | 0 bytes
peter | lookup_lsoa2011 | pg_toast_5055563 | | 1449 | 1.12 | 98.88 | 129068 | 0 bytes
peter | geometry_ews2011_geolevel_id_3_zoomlevel_6 | pg_toast_5055721 | | 1372 | 7.23 | 92.77 | 18976 | 0 bytes
pg_toast | pg_toast_5055721 | | geometry_ews2011_geolevel_id_3_zoomlevel_6 | 1342 | 9.73 | 90.27 | 13792 | 0 bytes
peter | geometry_ews2011_geolevel_id_4_zoomlevel_7 | pg_toast_5055771 | | 1298 | 4.40 | 95.60 | 29474 | 0 bytes
peter | geometry_ews2011_geolevel_id_3_zoomlevel_8 | pg_toast_5055741 | | 1206 | 4.03 | 95.97 | 29960 | 0 bytes
pg_toast | pg_toast_5055741 | | geometry_ews2011_geolevel_id_3_zoomlevel_8 | 1183 | 5.68 | 94.32 | 20811 | 0 bytes
pg_toast | pg_toast_5055761 | | geometry_ews2011_geolevel_id_4_zoomlevel_6 | 1118 | 6.58 | 93.42 | 16981 | 0 bytes
pg_toast | pg_toast_5055781 | | geometry_ews2011_geolevel_id_4_zoomlevel_8 | 1101 | 4.54 | 95.46 | 24256 | 0 bytes
pg_toast | pg_toast_5055891 | | geometry_ews2011_geolevel_id_7_zoomlevel_7 | 1073 | 9.06 | 90.94 | 11842 | 0 bytes
pg_toast | pg_toast_5055851 | | geometry_ews2011_geolevel_id_6_zoomlevel_7 | 1060 | 3.61 | 96.39 | 29337 | 0 bytes
peter | geometry_ews2011_geolevel_id_3_zoomlevel_7 | pg_toast_5055731 | | 911 | 4.06 | 95.94 | 22441 | 0 bytes
pg_toast | pg_toast_5055731 | | geometry_ews2011_geolevel_id_3_zoomlevel_7 | 891 | 5.71 | 94.29 | 15612 | 0 bytes
pg_toast | pg_toast_5055771 | | geometry_ews2011_geolevel_id_4_zoomlevel_7 | 788 | 4.40 | 95.60 | 17928 | 0 bytes
pg_toast | pg_toast_5055841 | | geometry_ews2011_geolevel_id_6_zoomlevel_6 | 763 | 5.56 | 94.44 | 13735 | 0 bytes
pg_toast | pg_toast_5055881 | | geometry_ews2011_geolevel_id_7_zoomlevel_6 | 710 | 11.73 | 88.27 | 6053 | 1632 kB
peter | geometry_ews2011_geolevel_id_2_zoomlevel_9 | pg_toast_5055711 | | 456 | 0.08 | 99.92 | 562259 | 0 bytes
pg_toast | pg_toast_5055711 | | geometry_ews2011_geolevel_id_2_zoomlevel_9 | 434 | 9.33 | 90.67 | 4651 | 0 bytes
peter | lookup_msoa2011 | pg_toast_5055555 | | 300 | 1.15 | 98.85 | 26001 | 0 bytes
peter | geometry_ews2011_geolevel_id_1_zoomlevel_9 | pg_toast_5055671 | | 296 | 0.05 | 99.95 | 561952 | 0 bytes
pg_toast | pg_toast_5055671 | | geometry_ews2011_geolevel_id_1_zoomlevel_9 | 278 | 6.20 | 93.80 | 4486 | 0 bytes
peter | geometry_ews2011_geolevel_id_2_zoomlevel_8 | pg_toast_5055701 | | 237 | 11.45 | 88.55 | 2070 | 0 bytes
peter | geometry_ews2011_geolevel_id_1_zoomlevel_8 | pg_toast_5055661 | | 221 | 9.74 | 90.26 | 2269 | 0 bytes
pg_toast | pg_toast_5055701 | | geometry_ews2011_geolevel_id_2_zoomlevel_8 | 221 | 14.16 | 85.84 | 1561 | 0 bytes
pg_toast | pg_toast_5055661 | | geometry_ews2011_geolevel_id_1_zoomlevel_8 | 208 | 11.36 | 88.64 | 1831 | 0 bytes
peter | geometry_ews2011_geolevel_id_2_zoomlevel_6 | pg_toast_5055681 | | 203 | 14.87 | 85.13 | 1365 | 0 bytes
pg_toast | pg_toast_5055681 | | geometry_ews2011_geolevel_id_2_zoomlevel_6 | 187 | 17.51 | 82.49 | 1068 | 0 bytes
peter | geometry_ews2011_geolevel_id_2_zoomlevel_7 | pg_toast_5055691 | | 177 | 11.76 | 88.24 | 1505 | 0 bytes
peter | geometry_ews2011_geolevel_id_1_zoomlevel_7 | pg_toast_5055651 | | 171 | 9.97 | 90.03 | 1716 | 0 bytes
pg_toast | pg_toast_5055691 | | geometry_ews2011_geolevel_id_2_zoomlevel_7 | 165 | 14.44 | 85.56 | 1143 | 0 bytes
pg_toast | pg_toast_5055651 | | geometry_ews2011_geolevel_id_1_zoomlevel_7 | 158 | 11.46 | 88.54 | 1379 | 0 bytes
peter | tile_intersects_ews2011_geolevel_id_2_zoomlevel_0 | pg_toast_5070572 | | 156 | 6.03 | 93.97 | 2588 | 0 bytes
peter | tile_intersects_ews2011_geolevel_id_1_zoomlevel_0 | pg_toast_5070556 | | 149 | 6.12 | 93.88 | 2435 | 0 bytes
pg_toast | pg_toast_5070572 | | tile_intersects_ews2011_geolevel_id_2_zoomlevel_0 | 148 | 8.11 | 91.89 | 1825 | 0 bytes
pg_toast | pg_toast_5070556 | | tile_intersects_ews2011_geolevel_id_1_zoomlevel_0 | 141 | 8.09 | 91.91 | 1743 | 0 bytes
peter | geometry_ews2011_geolevel_id_1_zoomlevel_6 | pg_toast_5055641 | | 134 | 7.81 | 92.19 | 1716 | 0 bytes
pg_toast | pg_toast_5055641 | | geometry_ews2011_geolevel_id_1_zoomlevel_6 | 120 | 8.31 | 91.69 | 1444 | 0 bytes
public | spatial_ref_sys | pg_toast_321436 | | 23 | 0.02 | 99.98 | 152022 | 0 bytes
peter | lookup_ladua2011 | pg_toast_5055547 | | 19 | 2.14 | 97.86 | 889 | 0 bytes
peter | geolevels_ews2011 | pg_toast_5055505 | | 9 | 7.63 | 92.37 | 118 | 0 bytes
peter | lookup_scntry2011 | pg_toast_5055523 | | 5 | 83.33 | 16.67 | 6 | 0 bytes
peter | geography_ews2011 | pg_toast_5055490 | | 5 | 16.13 | 83.87 | 31 | 0 bytes
peter | lookup_gor2011 | pg_toast_5055539 | | 4 | 15.38 | 84.62 | 26 | 0 bytes
peter | lookup_cntry2011 | pg_toast_5055531 | | 4 | 40.00 | 60.00 | 10 | 0 bytes
rif40 | t_rif40_parameters | | | 2 | 12.50 | 87.50 | 16 | 0 bytes
peter | tile_limits_ews2011 | pg_toast_5070536 | | 2 | 25.00 | 75.00 | 8 | 8192 bytes
peter | tile_limits_usa_2014 | pg_toast_626601 | | 2 | 100.00 | 0.00 | 2 | 0 bytes
(100 rows)
In this cases, somewhat later on in the processing:
- There are a number of small tables with with <90% cache hits;
- A large number the most hit tables are not buffered
These are both signs that the shared buffers needs to be increased for this workload.
Query Tuning
On Postgres the extract queries all do an EXPLAIN PLAN VERBOSE to the log:
+00037.83s [DEBUG1] rif40_execute_insert_statement(): [56005] SQL> EXPLAIN (VERBOSE, FORMAT text)
INSERT INTO s416_extract (
year,study_or_comparison,study_id,area_id,band_id,sex,age_group,test_1002,total_pop) /* 1 numerator(s) */
WITH n1 AS ( /* NUM_SAHSULAND_CANCER - cancer numerator */
SELECT s.area_id /* Study or comparision resolution */,
c.year,
c.age_sex_group AS n_age_sex_group,
SUM(CASE /* Numerators - can overlap */
WHEN (( /* Investigation 1 ICD filters */
icd LIKE 'C33%' /* Value filter */ /* Filter 1 */
OR icd LIKE 'C340%' /* Value filter */ /* Filter 2 */
OR icd LIKE 'C341%' /* Value filter */ /* Filter 3 */
OR icd LIKE 'C342%' /* Value filter */ /* Filter 4 */
OR icd LIKE 'C343%' /* Value filter */ /* Filter 5 */
OR icd LIKE 'C348%' /* Value filter */ /* Filter 6 */
OR icd LIKE 'C349%' /* Value filter */ /* Filter 7 */) /* 7 lines of conditions: study: 416, inv: 414 */
AND (1=1
AND c.year BETWEEN 1995 AND 1996/* Investigation 1 year filter */
/* No genders filter required for investigation 1 */
/* No age group filter required for investigation 1 */)
) THEN total
ELSE 0
END) inv_414_test_1002 /* Investigation 1 - */
FROM rif40_study_areas s, /* Numerator study or comparison area to be extracted */
num_sahsuland_cancer c /* cancer numerator */
WHERE c.sahsu_grd_level4 = s.area_id /* Study selection */
AND (
icd LIKE 'C33%' /* Value filter */ /* Filter 1 */
OR icd LIKE 'C340%' /* Value filter */ /* Filter 2 */
OR icd LIKE 'C341%' /* Value filter */ /* Filter 3 */
OR icd LIKE 'C342%' /* Value filter */ /* Filter 4 */
OR icd LIKE 'C343%' /* Value filter */ /* Filter 5 */
OR icd LIKE 'C348%' /* Value filter */ /* Filter 6 */
OR icd LIKE 'C349%' /* Value filter */ /* Filter 7 */)
/* No genders filter required for numerator (only one gender used) */
/* No age group filter required for numerator */
AND s.study_id = 416 /* Current study ID */
AND c.year = 1995 /* Numerator (INSERT) year filter */
GROUP BY c.year, s.area_id, s.band_id,
c.age_sex_group
) /* NUM_SAHSULAND_CANCER - cancer numerator */
, d AS (
SELECT d1.year, s.area_id, s.band_id, d1.age_sex_group,
SUM(COALESCE(d1.total, 0)) AS total_pop
FROM rif40_study_areas s, pop_sahsuland_pop d1 /* Denominator study or comparison area to be extracted */
WHERE d1.year = 1995 /* Denominator (INSERT) year filter */
AND s.area_id = d1.sahsu_grd_level4 /* Study geolevel join */
AND s.area_id IS NOT NULL /* Exclude NULL geolevel */
AND s.study_id = 416 /* Current study ID */
/* No age group filter required for denominator */
GROUP BY d1.year, s.area_id, s.band_id,
d1.age_sex_group
) /* End of denominator */
SELECT d.year,
'S' AS study_or_comparison,
416 AS study_id,
d.area_id,
d.band_id,
TRUNC(d.age_sex_group/100) AS sex,
MOD(d.age_sex_group, 100) AS age_group,
COALESCE(n1.inv_414_test_1002, 0) AS inv_414_test_1002,
d.total_pop
FROM d /* Denominator - population health file */
LEFT OUTER JOIN n1 ON ( /* NUM_SAHSULAND_CANCER - cancer numerator */
d.area_id = n1.area_id
AND d.year = n1.year
AND d.age_sex_group = n1.n_age_sex_group
)
ORDER BY 1, 2, 3, 4, 5, 6, 7;
+00038.04s [DEBUG1] rif40_execute_insert_statement(): [56602] Study ID 416, statement: 15
Description: Study extract insert 1995 (EXPLAIN)
query plan:
Insert on rif_studies.s416_extract (cost=19943.90..21263.53 rows=52785 width=588)
-> Subquery Scan on "*SELECT*" (cost=19943.90..21263.53 rows=52785 width=588)
Output: "*SELECT*".year, "*SELECT*".study_or_comparison, "*SELECT*".study_id, "*SELECT*".area_id, "*SELECT*".band_id, "*SELECT*".sex, "*SELECT*".age_group, "*SELECT*".inv_414_test_1002, "*SELECT*".total_pop
-> Sort (cost=19943.90..20075.86 rows=52785 width=544)
Output: d.year, ('S'::text), (416), d.area_id, d.band_id, (trunc(((d.age_sex_group / 100))::double precision)), (mod(d.age_sex_group, 100)), (COALESCE(n1.inv_414_test_1002, '0'::bigint)), d.total_pop
Sort Key: d.year, d.area_id, d.band_id, (trunc(((d.age_sex_group / 100))::double precision)), (mod(d.age_sex_group, 100))
CTE n1
-> HashAggregate (cost=2789.39..2818.90 rows=2951 width=36)
Output: s.area_id, c.year, c.age_sex_group, sum(CASE WHEN ((((c.icd)::text ~~ 'C33%'::text) OR ((c.icd)::text ~~ 'C340%'::text) OR ((c.icd)::text ~~ 'C341%'::text) OR ((c.icd)::text ~~ 'C342%'::text) OR ((c.icd)::text ~~ 'C343%'::text) OR ((c.icd)::text ~~ 'C348%'::text) OR ((c.icd)::text ~~ 'C349%'::text)) AND (c.year >= 1995) AND (c.year <= 1996)) THEN c.total ELSE 0 END), s.band_id
Group Key: c.year, s.area_id, s.band_id, c.age_sex_group
-> Hash Join (cost=2094.27..2686.10 rows=2951 width=36)
Output: s.area_id, s.band_id, c.year, c.age_sex_group, c.icd, c.total
Hash Cond: ((c.sahsu_grd_level4)::text = (s.area_id)::text)
-> Index Scan using num_sahsuland_cancer_year on rif_data.num_sahsuland_cancer c (cost=0.42..548.20 rows=2909 width=32)
Output: c.year, c.age_sex_group, c.sahsu_grd_level1, c.sahsu_grd_level2, c.sahsu_grd_level3, c.sahsu_grd_level4, c.icd, c.total
Index Cond: (c.year = 1995)
Filter: (((c.icd)::text ~~ 'C33%'::text) OR ((c.icd)::text ~~ 'C340%'::text) OR ((c.icd)::text ~~ 'C341%'::text) OR ((c.icd)::text ~~ 'C342%'::text) OR ((c.icd)::text ~~ 'C343%'::text) OR ((c.icd)::text ~~ 'C348%'::text) OR ((c.icd)::text ~~ 'C349%'::text))
-> Hash (cost=2078.15..2078.15 rows=1256 width=20)
Output: s.area_id, s.band_id
-> Subquery Scan on s (cost=2062.45..2078.15 rows=1256 width=20)
Output: s.area_id, s.band_id
-> Sort (cost=2062.45..2065.59 rows=1256 width=26)
Output: c_1.username, (NULL::integer), c_1.area_id, c_1.band_id
Sort Key: c_1.username
InitPlan 1 (returns $0)
-> Seq Scan on pg_catalog.pg_authid a (cost=0.00..6.23 rows=1 width=64)
Output: upper(((a.rolname)::information_schema.sql_identifier)::text)
Filter: (pg_has_role(a.oid, 'USAGE'::text) AND (upper(((a.rolname)::information_schema.sql_identifier)::text) = 'RIF_MANAGER'::text))
-> Nested Loop Left Join (cost=0.70..1991.57 rows=1256 width=26)
Output: c_1.username, NULL::integer, c_1.area_id, c_1.band_id
Join Filter: (c_1.study_id = s_1.study_id)
Filter: (((c_1.username)::name = "current_user"()) OR ('RIF_MANAGER'::text = $0) OR ((s_1.grantee_username IS NOT NULL) AND ((s_1.grantee_username)::text <> ''::text)))
-> Index Scan using t_rif40_study_areas_pk on rif40.t_rif40_study_areas c_1 (cost=0.42..1948.73 rows=1256 width=30)
Output: c_1.username, c_1.study_id, c_1.area_id, c_1.band_id
Index Cond: (c_1.study_id = 416)
-> Materialize (cost=0.27..8.30 rows=1 width=10)
Output: s_1.study_id, s_1.grantee_username
-> Index Only Scan using rif40_study_shares_pk on rif40.rif40_study_shares s_1 (cost=0.27..8.30 rows=1 width=10)
Output: s_1.study_id, s_1.grantee_username
Index Cond: (s_1.study_id = 416)
Filter: ((s_1.grantee_username)::name = "current_user"())
CTE d
-> HashAggregate (cost=5946.13..6473.98 rows=52785 width=32)
Output: d1.year, s_2.area_id, s_2.band_id, d1.age_sex_group, sum(COALESCE(d1.total, 0))
Group Key: d1.year, s_2.area_id, s_2.band_id, d1.age_sex_group
-> Hash Join (cost=2097.41..5273.88 rows=53780 width=32)
Output: s_2.area_id, s_2.band_id, d1.year, d1.age_sex_group, d1.total
Hash Cond: ((d1.sahsu_grd_level4)::text = (s_2.area_id)::text)
-> Index Scan using pop_sahsuland_pop_year on rif_data.pop_sahsuland_pop d1 (cost=0.43..2375.17 rows=52785 width=28)
Output: d1.year, d1.age_sex_group, d1.sahsu_grd_level1, d1.sahsu_grd_level2, d1.sahsu_grd_level3, d1.sahsu_grd_level4, d1.total
Index Cond: (d1.year = 1995)
-> Hash (cost=2081.29..2081.29 rows=1256 width=20)
Output: s_2.area_id, s_2.band_id
-> Subquery Scan on s_2 (cost=2065.59..2081.29 rows=1256 width=20)
Output: s_2.area_id, s_2.band_id
-> Sort (cost=2065.59..2068.73 rows=1256 width=26)
Output: c_2.username, (NULL::integer), c_2.area_id, c_2.band_id
Sort Key: c_2.username
InitPlan 3 (returns $2)
-> Seq Scan on pg_catalog.pg_authid a_1 (cost=0.00..6.23 rows=1 width=64)
Output: upper(((a_1.rolname)::information_schema.sql_identifier)::text)
Filter: (pg_has_role(a_1.oid, 'USAGE'::text) AND (upper(((a_1.rolname)::information_schema.sql_identifier)::text) = 'RIF_MANAGER'::text))
-> Nested Loop Left Join (cost=0.70..1994.71 rows=1256 width=26)
Output: c_2.username, NULL::integer, c_2.area_id, c_2.band_id
Join Filter: (c_2.study_id = s_3.study_id)
Filter: (((c_2.username)::name = "current_user"()) OR ('RIF_MANAGER'::text = $2) OR ((s_3.grantee_username IS NOT NULL) AND ((s_3.grantee_username)::text <> ''::text)))
-> Index Scan using t_rif40_study_areas_pk on rif40.t_rif40_study_areas c_2 (cost=0.42..1951.87 rows=1256 width=30)
Output: c_2.username, c_2.study_id, c_2.area_id, c_2.band_id
Index Cond: ((c_2.study_id = 416) AND (c_2.area_id IS NOT NULL))
-> Materialize (cost=0.27..8.30 rows=1 width=10)
Output: s_3.study_id, s_3.grantee_username
-> Index Only Scan using rif40_study_shares_pk on rif40.rif40_study_shares s_3 (cost=0.27..8.30 rows=1 width=10)
Output: s_3.study_id, s_3.grantee_username
Index Cond: (s_3.study_id = 416)
Filter: ((s_3.grantee_username)::name = "current_user"())
-> Merge Left Join (cost=5425.21..6510.61 rows=52785 width=544)
Output: d.year, 'S'::text, 416, d.area_id, d.band_id, trunc(((d.age_sex_group / 100))::double precision), mod(d.age_sex_group, 100), COALESCE(n1.inv_414_test_1002, '0'::bigint), d.total_pop
Merge Cond: (((d.area_id)::text = (n1.area_id)::text) AND (d.year = n1.year) AND (d.age_sex_group = n1.n_age_sex_group))
-> Sort (cost=5196.11..5328.08 rows=52785 width=536)
Output: d.year, d.area_id, d.band_id, d.age_sex_group, d.total_pop
Sort Key: d.area_id, d.year, d.age_sex_group
-> CTE Scan on d (cost=0.00..1055.70 rows=52785 width=536)
Output: d.year, d.area_id, d.band_id, d.age_sex_group, d.total_pop
-> Sort (cost=229.10..236.48 rows=2951 width=532)
Output: n1.inv_414_test_1002, n1.area_id, n1.year, n1.n_age_sex_group
Sort Key: n1.area_id, n1.year, n1.n_age_sex_group
-> CTE Scan on n1 (cost=0.00..59.02 rows=2951 width=532)
Output: n1.inv_414_test_1002, n1.area_id, n1.year, n1.n_age_sex_group
+00038.28s rif40_execute_insert_statement(): [56605] Study 416: Study extract insert 1995 (EXPLAIN) OK, took: 00:00:00.061771
Database Space Management
Postrgres needs to be VACUUM to clear out dead tuples as it has no rollback segments. VACUUM reclaims storage occupied by dead tuples. In normal PostgreSQL operation,
tuples that are deleted or obsoleted by an update are not physically removed from their table; they remain present until a VACUUM is done. Therefore it’s necessary to do
VACUUM periodically, especially on frequently-updated tables. An [Auto Vacuum]https://www.postgresql.org/docs/9.6/static/routine-vacuuming.html#AUTOVACUUM)
daemon is provided for this purpose. If you do NOT do this you will eventually run out of disk space. After about Postgres 9.3 or so he system will launch autovacuum processes
if necessary to prevent transaction ID wraparound.
autovacuum = on # Enable autovacuum subprocess? 'on'
# requires track_counts to also be on.
track_counts = on
Vaccuming can also be carried out using the vacuumdb command or by using the SQL
VACUUM command: VACCUM FULL VERBOSE ANALYZE will garbage-collect and analyze a database verbosely.
SQL Server
Server Memory Tuning
SQL Server automatically allocates memory as needed by the server up to the limit of 2,147,483,647MB! In practice you may wish to reduce this figure to 40% of the available RAM.
By default SQL Server is not using largepages (the names for huge_pages in SQL Server):
1> SELECT large_page_allocations_kb FROM sys.dm_os_process_memory;
2> go
large_page_allocations_kb
-------------------------
0
To enable largepages you need to Enable the Lock Pages in Memory Option.
This will have consequences for the automated tuning which unless limited in size will remove the ability of Windows to free up SQL Server memory for other applications (and Windows itself). You need to be on a
big server and make sure your memory set-up is stable before enabling it.
Query Tuning
The SQL Server profiler needs to be used to trace RIF application tuning.
To use the profiler you will need to be a sysadmin or have the ALTER TRACE role: GRANT ALTER TRACE TO peter;
Show execution plan in SQL Server management studio is also very effective (showing missing indexes) and allows analysis of running queries:
However it is not very effective as it did not spot that the query had effectively disabled the SPATIAL indexes. The real problem with the query was the lack of partitioning on SQL Server.
When the query was split by geolevel_id it ran in two minutes as opposed to >245 hours!. It also cannot cope with T-SQL.
Database Space Management
SQL Server should not need VACUUMing like Postgres as it uses rollback segments. However the database can run out of space as
space stays with tables once allocated; databases need to be shrunk periodically: .
Note that the database will NOT shrink unless you back it up.
The option reorganise files before releasing unused space will affect performance and will take a long like (2x as long as a Postgres VACUUM FULL).
Peter Hambly, November 2018