
Our Advice: Improving administrative systems used to capture address histories
by Kevin Garwood
There are three main kinds of improvements that can be made to administrative systems so that their residential address histories will better support retrospective exposure studies:- form comments
- guided data entry features
- validation features
We assume that there would be scarce developer resources available for cohorts to create or improve administrative systems they use to maintain contact details of their study members. For small cohorts, it is likely that such systems would begin as simple spread sheets, and would evolve into tables that are managed through a database. Eventually cohort members would be able to add, edit and delete current addresses using electronic forms that support guided data entry and validation features. Large cohorts may invest in web-based applications as part of delegating the task of updating changes of address to the study members themselves.
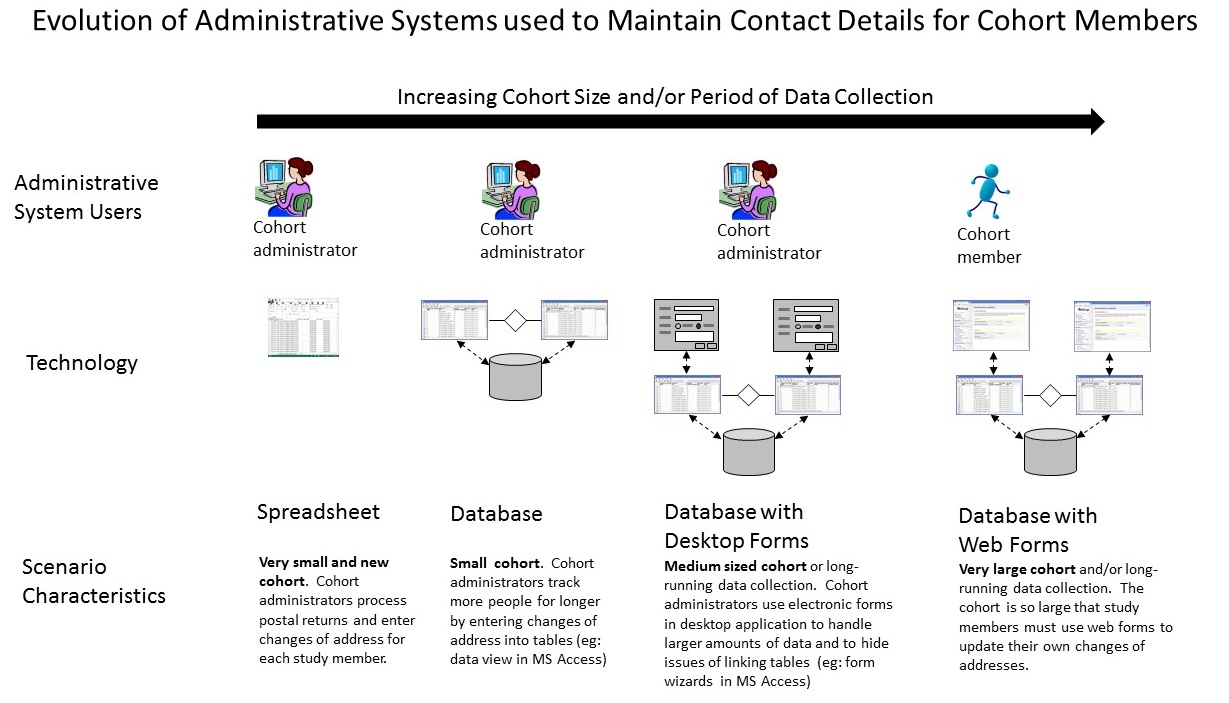
Apart from evolving through different technologies, the administrative systems may evolve new features as it goes from being a means of auditing current addresses to a means of tracking past addresses. Initially, the start date of an address period would likely be the time stamp that is generated when the application creates a new record. The end date of the address period may be calculated as the day before the creation time stamp of the next record.
In the following sections, we explain a sequence of incremental improvements that can improve the data quality of residential address histories that would later be taken from the contact database systems. Cohorts may decide to make different improvements, depending on their available developer resources and on the needs of any legacy contacts applications they may already be using.
General Advice
Use alphanumeric study member identifiers instead of auto-incremented numbers
The study member identifier is the most important data field in ALGAE because it links together different sources of information about the same person. The way the identifiers are generated can influence how error-prone it is to link related records together and how easy it will later be to migrate data from one information management system to the next.Using auto-numbering to generate new study identifiers is appealing because it is simple. In spreadsheets, it may be tempting to borrow the line number that appears next to the first field. In database programs such as MS Access, it is easy to create a primary key that uses an autonumbering feature.
The problem with using auto-generated identifiers is that when they are used in different tables, there is a risk that accidentally linking the wrong fields will still produce matches that obscure the mistake.
Consider the following example of where we make an error by accidentally linking
study member and current address tables using
study_member_data.id=current_addresses.id instead of
study_member_data.id=current_addresses.study_member_id.
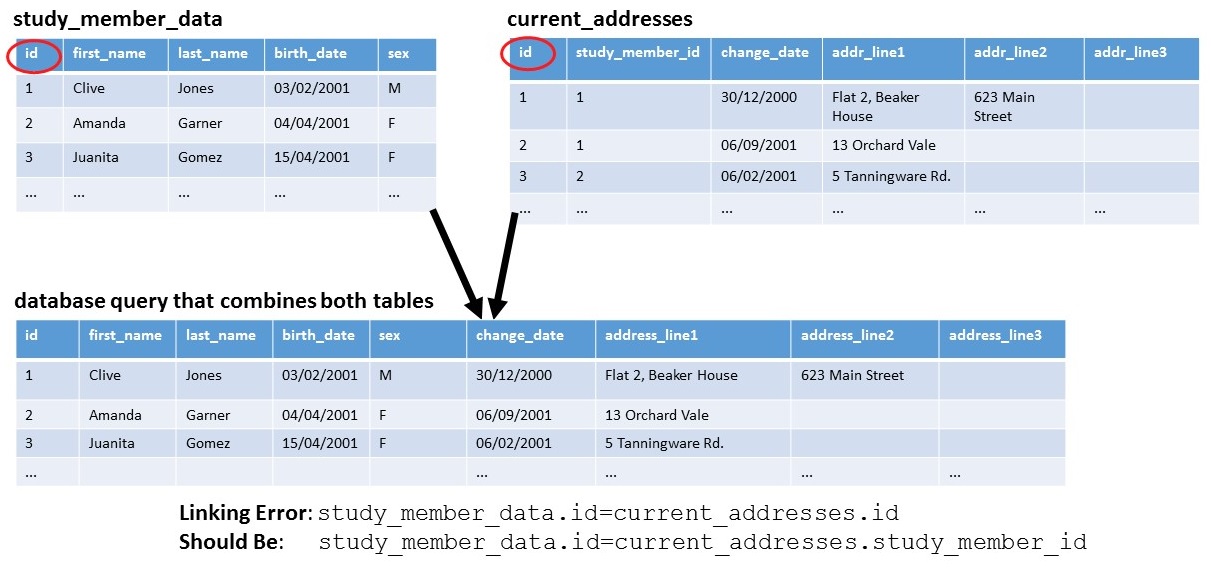
The resulting database query may return addresses for most study members and create
the impression that it has correctly created address histories for each person.
There is a possibility that during some important life stage, Amanda Garner's
exposure will be assessed at 13 Orchard Vale instead of
5 Tanningware Rd. It is also possible that exposure scientists
would never detect the error and that epidemiologists might then observe incorrect
relationships between early life exposure and later life health outcomes.
Now consider the same scenario, but where the identifier field in the
study_member_data has a value that is not assigned a unique value
through an auto-numbering feature. When the query is run, it will produce no results,
thereby indicating an obvious problem that needs to be fixed.
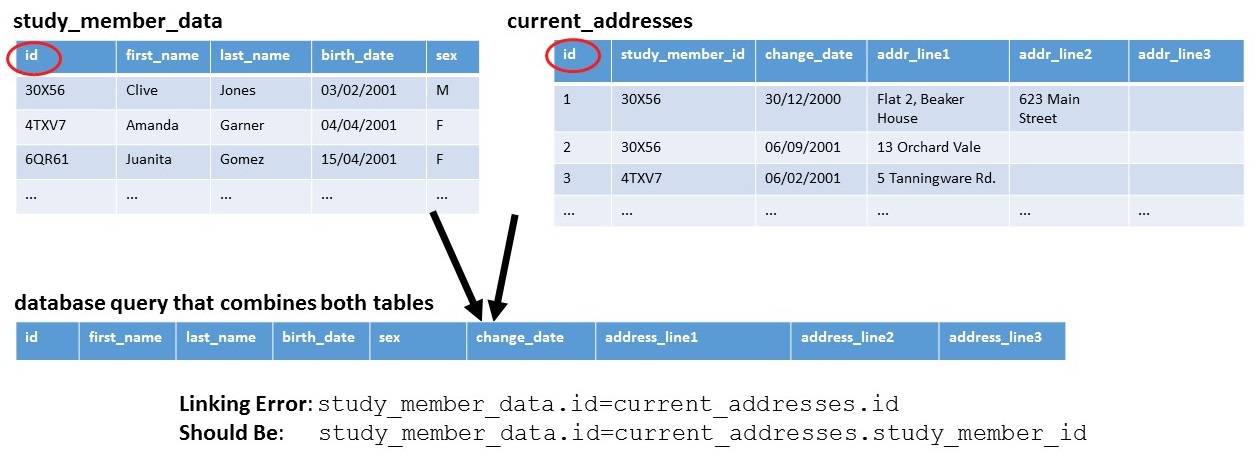
As technologies change, cohorts may feel compelled to migrate administrative data from one kind of information management system to another. Auto-generated keys are usually unique with respect to a particular table but may not be unique when they are used within a new system. For example, if administrators use a new database to recruit a new group of cohort members and then import cohort member data from another database, they may find that multiple people are assigned the same study identifier.
Design study member identifiers to resist typographical mistakes
If your staff are going to be manually typing in study member identifiers, then it is a good idea to generate ones that will be guaranteed to be at least two characters different than any other identifier.For example, consider the study member identifiers 101D assigned to one person and 151D assigned to another. If cohort staff were to accidentally type in 151D but actually mean 101D, then a record could end up being assigned to another person. It is much easier to spot data linkage errors if the typographical mistakes produce identifiers that don't belong to anyone.
One way to reduce the risk of typographical mistakes is to alternate number and letter characters. The alternation between letters and number helps slow down data entry so that key strokes become more deliberate. Another way to reduce the likelihood of undetected typographical errors is to choose identifiers that have many characters and produce far more possible identifiers than are needed by the size of the cohort.
Include an audit trail feature to retain old current addresses
However you record the current address of your cohort members, you should ensure that your system audits past current address records rather than just maintaining only the most recent one. We have learned of cohorts whose administrative systems did not do this, and they are left with the challenge of relying on a single postal address to represent the entire exposure time frame that is used within a particular study.When having the one address is no longer sufficient to support these studies, the cohorts are usually left with no choice other than to commission a data collection sweep that elicits past addresses from study members. This approach is prone to problems related to memory recall and response rates.
Having an audit trail in your system provides at least two benefits. First, it can help establish which addresses a cohort used when it mailed out sensitive data to its members. An audit trail can help support various reviews that may be part of information governance procedures. Second, the audit trail provides a way of recording movement patterns that could later be used as well or in place of an expensive questionnaire effort to accomplish the same thing.
Improving Spreadsheets
If your project is recording changes of addresses using a spreadsheet, then you may want to change the date format so that the dates are spelled rather than numbered. Entering dates using formats such asdd/MM/yyyy or
MM/dd/yyyy are prone to problems of transposing numbers and
having the data interpretted differently between American and European formats.
In data entry activities, it is much easier to understand the meaning of
09 JUN 2002 than 09/06/2002

A spreadsheet may be an acceptable means of recording a few address changes at the beginning of recruitment for a very small cohort. However, spreadsheets have a number of drawbacks:
- manual data entry is prone to typographical errors and the field errors can affect data linking and filtering activities
- tables may include additional description fields to help data enterers know whose records they are editing
- the repetitious nature of data entry may make staff more at risk of creating errors from copy-and-paste operations.
- auditing manual data corrections is laborious
I would expect that almost any cohort project having more than a few cohort members will soon invest in using a database that is edited through electronic forms.