
Preparing Cohort Data
by Kevin Garwood
At a high level, the basic steps of the ALGAE protocol are described in the following diagram. In Step 1, you will need to select your study members from the cohort. Usually they will have to meet the criterion that they lived in the exposure time frame continually for the duration of the time frame of the analysis.You may also decide to insist that the study members must have lived continually for the duration of the time frames for both early life and later life analyses. Furthermore, some studies may require that the study members still be alive.
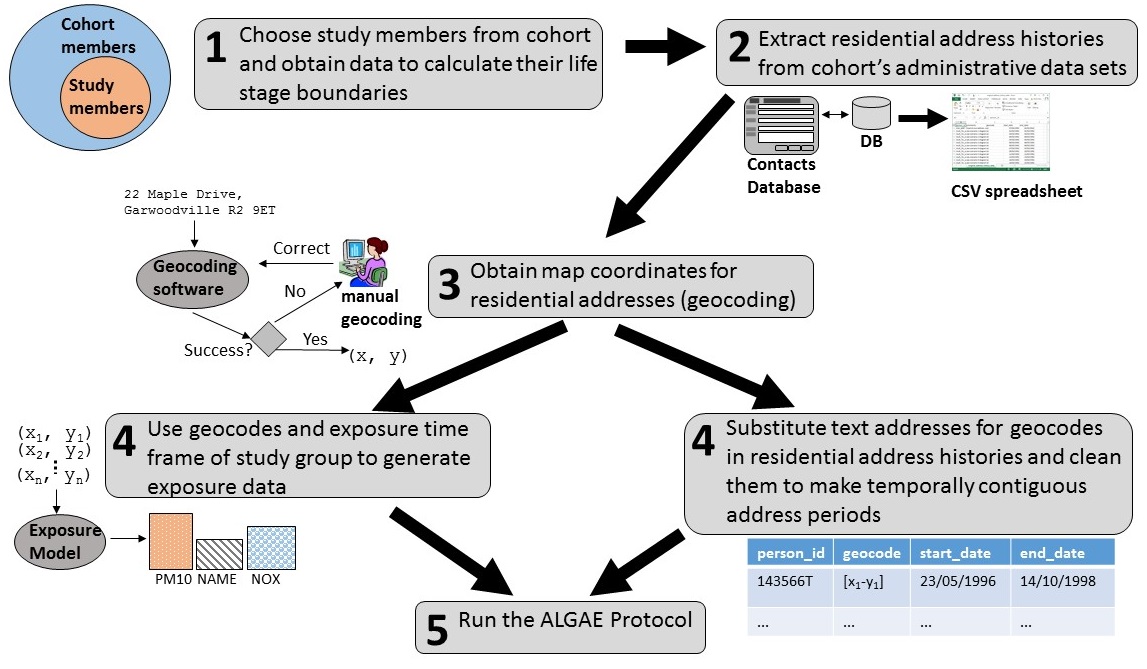
However you choose the study members, you will need to obtain data that will allow
the start of any analysis to begin at conception. For example, the default
implementation of the protocol requires birth_date and
best_gest (gestation age at birth) to calculate conception date
(See Calculations and
Algorithms to understand how the calculation for conception date works).
In Step 2, you will need to extract residential histories for your study members from whatever system a cohort may be using to track the current addresses of its members. You'll probably have to export a table of audited addresses to a CSV spreadsheet that can be easily processed by other programs.
In Step 3, you will determine geocodes for each residential address. Usually you will need to ensure that the addresses are put into some canonical format so that they are amenable to being processed by geocoding software applications. The software will likely fail to geocode some addresses, so you may have to either correct the residential address entries and run the software again, or try to work out the map coordinates manually.
The outcome of geocoding the addresses will serve as inputs for Step 4, which involves two activities that can be done in parallel. In the first activity, the geocodes serve as inputs for an exposure model, which generates pollution values for the locations at given intervals. For the early life analysis, we expect that the exposure values will represent daily exposure records. For the later life analysis, we expect that the exposure values will represent annual average values.
In the other activity, we will substitute text-based residential address fields with geocodes and then produce the table which will describe all the address periods that ALGAE will use to determine where someone was living and when.
In Step 5, we will run ALGAE based on four data tables that are described in the tables below. You should now try to look at the steps for producing each table in greater detail.
| Table | Fields | Description |
|---|---|---|
| original_study_member_data | Describes data to help establish life stage boundaries of study members. Also contains data to help determine how confident we can be about certain assumptions about the residential address history data. | |
| original_geocode_data | Describes data quality flags associated with geocoding residential addresses. Also associates geocodes with identifiers for administrative areas that contain the geocode, in order to help researchers link exposures with geographical covariate data (eg: socio-economic level, education level, smoking etc). | |
| original_address_history_data | person_id, comments, birth_date, best_gest, absent_during_exp, at_1st_addr_conception | Describes the location, start date and end date of address periods which tell ALGAE where people were and when. |
| original_exposure_data | geocode, comments, date_of_year, pm10_rd, nox_rd, pm10_gr, name, pm10_tot | Describes pollution exposure values for a given date. In the early life analysis, they describe daily exposure values. In the later life analysis, they describe annual average values that are set for January 1st of a given year. |
Begin your detailed tour of preparing cohort data for ALGAE
Now we'll revisit the main steps you'll need to complete in order to prepare ALGAE to process data from your cohort.
| Data loading part 1: Prepare study member data |
| Data loading part 2: Prepare the geocode data |
| Data loading part 3: Prepare address history data |
| Data loading part 4: Prepare the exposure data |