
Main Use Case Theme
by Kevin Garwood and Daniela Fecht
ALGAE was originally developed to support a specific environmental health study. It was later generalised generalised both in response to the computing environment in which it was deployed and in response to growing interest from other environmental health researchers who may want to use it. Here we provide the setting for why the protocol was developed and then describe some of its main features.
Examining the Relationship between Early Life Exposures and Later Life Health
There is a growing interest about air pollution exposure during early life stages and potential influences on health in later life. This protocol, developed as part of an Imperial College-led study, establishes where members of the ALSPAC cohort lived during early life stages and the air pollution concentrations they were exposed to at each residential address.The study members are part of a mature cohort study, and one of the biggest challenges has been to establish exactly where study members lived and when they lived there, and if they lived within our study area. Today, we have various technologies that can track the movement patterns of people. But in the early 1990s, when the study members were born, one of the best available sources of movement pattern data came from an administrative database.
In order to support its correspondence activities with cohort members, ALSPAC maintained such an administrative database that audited the cohort members' current addresses. Years later, this auditing of addresses would help Imperial College and ALSPAC to determine where study members were in relation to variations of historical pollution concentrations.
The ALGAE protocol was developed to bring together historically assessed exposure data and the residential address histories that have been derived from the changes of address that have been maintained in ALSPAC's Contacts facilities. ALGAE's role is to provide a piece of software infrastructure that can support future early life exposure studies.
Main Use Case
System and Workflows
In the original Imperial-led study, results were generated by coordinating two separate bodies of code: a cohort-specific code base and the generic code base (ALGAE).In the cohort-specific scripts, code would extract data from various files and store it in a set of canonical tables that would be used to drive the activity of the generic ALGAE protocol. The system view is shown below: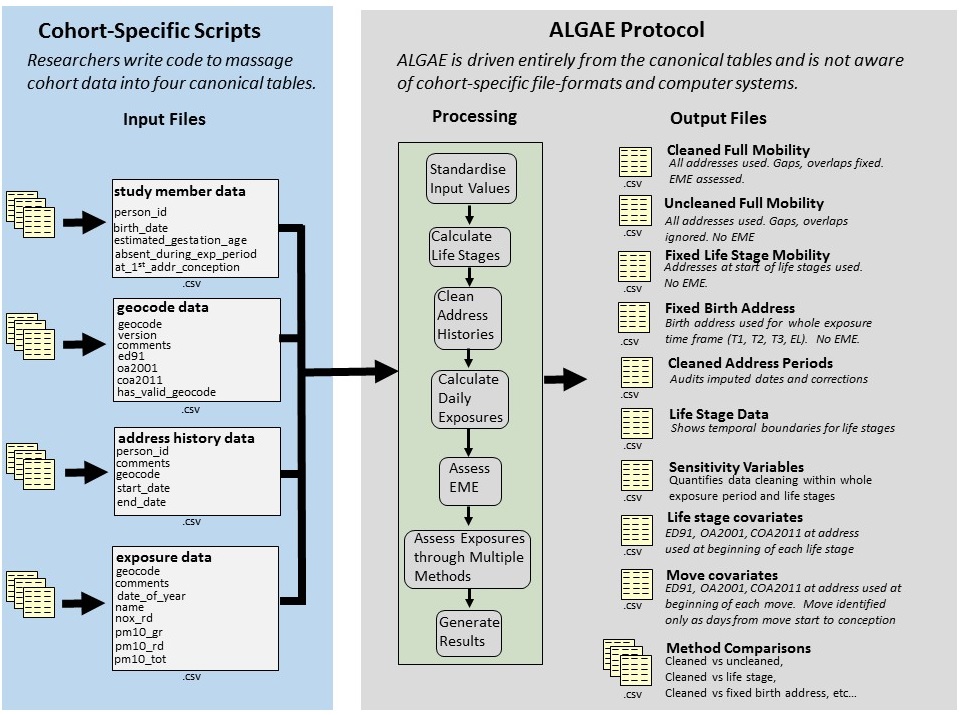
The main activities of ALGAE are described in the work flow that is shown
in the middle of the diagram. Making the assumption that input data were
organised into tables the way the it expected, the protocol would first
standardise input values. Most of this activity involves converting
different valid ways of representing data into a single representation. For
example, in "Yes/No" fields, it ensures that y, Y, Yes, YES, TRUE, true, 1
are all changed to Y. As another example, it ensures that null geocode
values such as NULL, #NULLIF, and empty_geocode.
Next, it uses data from the study_member_data to calculate life stages.
This is where it uses the birth_date and gestation_age_at_birth
fields to calculate the study member's conception date. For the early life analyIt then uses conception date
to calculate the start and end dates of preganancy trimesters. In the later life
analysis, it uses the birth date to help define years of life stages.
Once the life stages have been calculated, the protocol cleans address histories. Here ALGAE tries to correct any blank start or end dates, orders them and corrects any problems it finds in the address period records. It audits whatever it changes.
In the calculate daily exposures phase, ALGAE links the cleaned address periods with daily exposure data to determine what exposure study members had for a given pollutant on a given day at the location they occupied on that day.
In the assess EME stage, ALGAE tries to assess the exposure measurement error for each day in the study members' exposure time frames. It uses the audits of gaps and overlaps that were made in the address histories to produce an opportunity cost measure for each day. During cleaning, if these temporal fit problems occur between two successive address period, ALGAE assigns those days to one or the other periods. The EME value measures the difference between the exposure of the cleaned location and the exposure it could have had at the other alternative location.
Next, ALGAE assesses exposures through multiple methods. Each method decides which exposure records it should use from the last step to use in calculations that aggregate daily exposure values. In the cleaned mobility assessment, contributions from all address periods used in a life stage are used to produce a life stage exposure. In the life stage mobility assessment, the location on the first day of exposure is used to represent location for the entire life stage. In the early life analysis, there is also the birth address assessment, which uses the birth address to represent the entire exposure time frame.
Finally, the protocol generates results by writing result tables to CSV files. In this part of the process, it also assigns naming conventions in the variable names which can be referenced in the data dictionary.
Logistical Considerations
One of the most important factors which influenced protocol development were information governance considerations. ALSPAC's information governance policies meant that although Imperial College could generate exposure data, it could only link that data with residential address histories and study member data on-site at the cohort's facilities in Bristol. That restriction required us to arrange week long site visits in Bristol.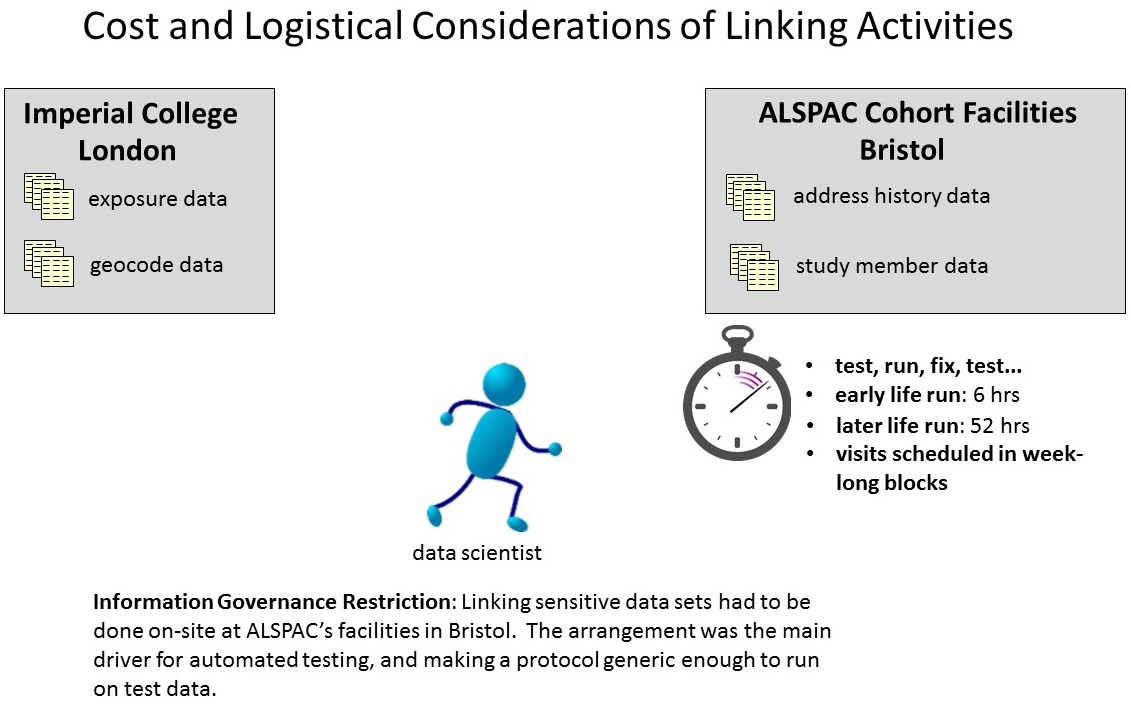
Given the length of time it would often take to complete a run, there was great incentive to minimise the amount of programming work that had to be done onsite there. In order to test ALGAE offsite, it was necessary to make it able to drive completely off fake test data. That in turn led to the isolation of generic protocol code, the development of automated test suites, and a generalisation of concepts that would allow it to be run on another cohort in another study. In many ways, ALGAE was created to minimise business costs associated with doing sensitive data linking at an off-site facility, where the effects of linking were often unknown until the week of the visit.